AI Task平台使用手册
实验流程_平台可视化版本
01-数据工程
02-复制算法
03-模型训练
04-模型推理
05-模型编译
06-模型下载并固化
07-本地推理
08-附:镜像配置与保存
实验流程_NoteBook版本
01-数据工程
02-算法创建
03-模型训练
04-模型推理
05-模型编译
06-模型下载并固化
07-本地推理
08-附:镜像配置与保存
本文档使用 MrDoc 发布
-
+
首页
03-模型训练
3.1当算法复制好后,进入训练管理菜单,选择创建任务 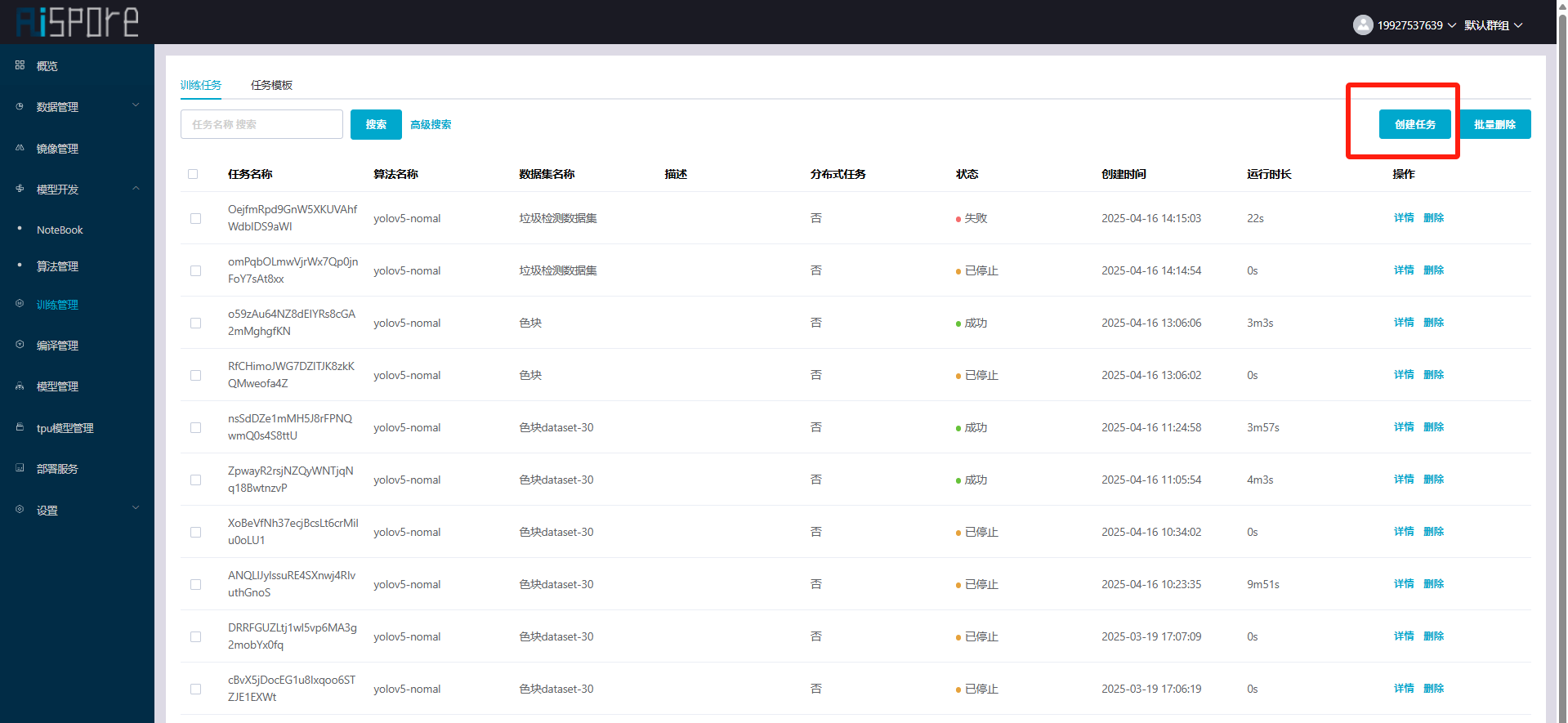 3.2训练任务创建,填入要求信息与运行命令,点击开始训练,参考如下图 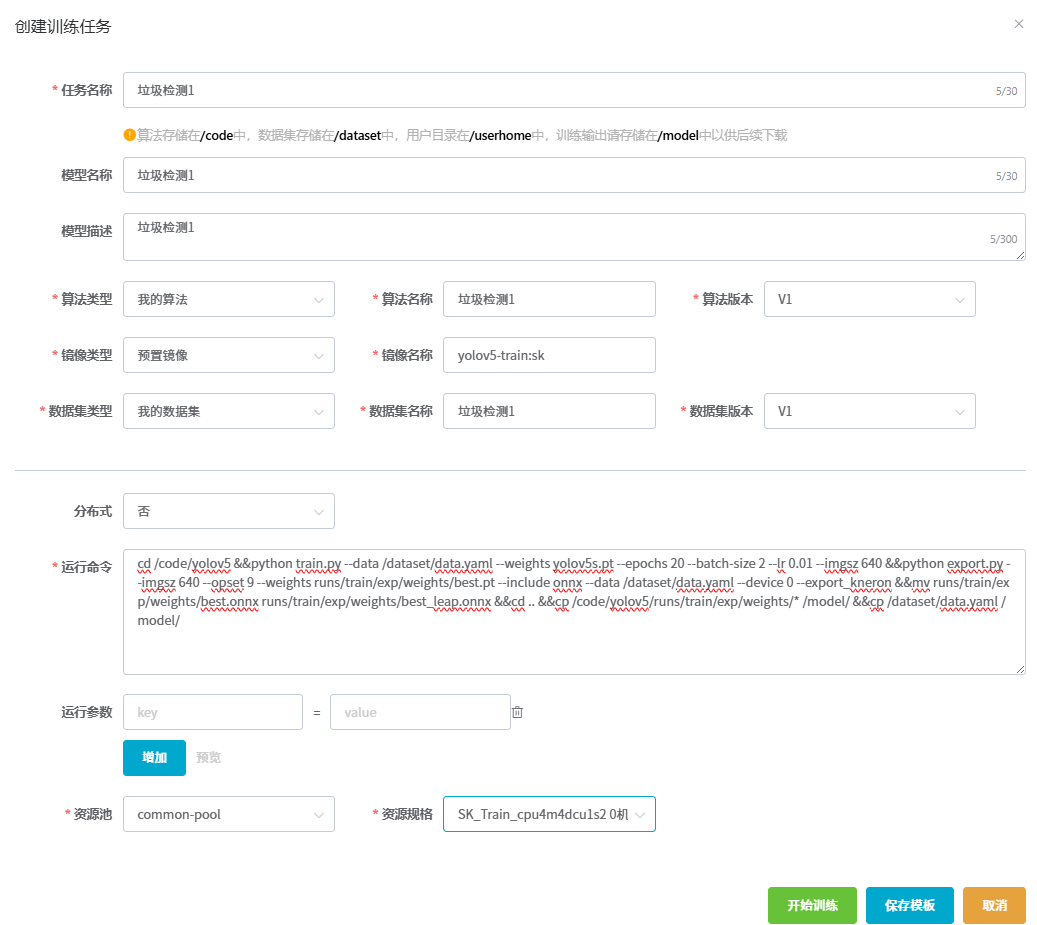 TPU类型为AMC: 将以下代码复制填入运行命令中: set -ex; echo "export LD_LIBRARY_PATH=/usr/local/corex/lib64:$LD_LIBRARY_PATH">> /root/.bashrc&& numa_id=$(ixsmi topo -m | awk "NR==2 {print \$NF}"); numa_id=$(echo $numa_id | awk "{print \$NF}"); echo $numa_id; ixsmi; ixsmi topo -m; echo "numa_id:$numa_id";cd /code/yolov5;numactl --cpunodebind=$numa_id --membind=$numa_id python3 train.py --data /dataset/data.yaml --weights yolov5s.pt --epochs 20 --batch-size 2 --lr 0.01 --imgsz 640;numactl --cpunodebind=$numa_id --membind=$numa_id python3 export.py --imgsz 640 --opset 9 --weights runs/train/exp/weights/best.pt --include onnx --data /dataset/data.yaml --device cpu --export_kneron;cp runs/train/exp/weights/best.onnx runs/train/exp/weights/best_kneron.onnx;numactl --cpunodebind=$numa_id --membind=$numa_id python3 export.py --imgsz 640 --weights runs/train/exp/weights/best.pt --include torchscript --device cpu;cd ..;mv yolov5/runs/train/exp/weights/best.torchscript yolov5/runs/train/exp/weights/best.torchscript.pt;torch-model-archiver --model-name best --version 1.0 --serialized-file yolov5/runs/train/exp/weights/best.torchscript.pt --handler yolov5_model_handler.py --extra-files /dataset/data.yaml,yolov5/runs/train/exp/weights/best.onnx;cp /code/yolov5/runs/train/exp/weights/* /model/;cp /dataset/data.yaml /model/;cp /code/best.mar /model/ ==运行命令具体含义如下:== 3.2.1`set -ex` 启用严格模式。 3.2.2`echo "export LD_LIBRARY_PATH=/usr/local/corex/lib64:$LD_LIBRARY_PATH" >> /root/.bashrc` 将 corex 库路径永久添加到环境变量。 3.2.3`numa_id=$(ixsmi topo -m | awk "NR==2 {print \$NF}");numa_id=$(echo $numa_id | awk "{print \$NF}");` 解析硬件拓扑信息,获取当前 NUMA 节点 ID。 3.2.4`echo $numa_id; ixsmi; ixsmi topo -m; echo "numa_id:$numa_id";` 打印 NUMA 节点 ID 和硬件拓扑信息。 --cpunodebind: 限制进程的 CPU 核心在指定 NUMA 节点上运行。 --membind: 强制进程内存分配在指定 NUMA 节点的内存区域。 3.2.5`cd /code/yolov5;numactl --cpunodebind=$numa_id --membind=$numa_id python3 train.py --data /dataset/data.yaml --weights yolov5s.pt --epochs 20 --batch-size 2 --lr 0.01 --imgsz 640;` 在指定 NUMA 节点上训练模型。 numactl:绑定进程到特定 NUMA 节点(优化内存访问延迟)。 --cpunodebind=$numa_id:限制 CPU 核心在指定 NUMA 节点。 --membind=$numa_id:限制内存分配在指定 NUMA 节点。 --data: 数据集配置文件路径。 --weights: 预训练权重文件。 --epochs: 训练总轮数。 --batch-size: 每个批次的图像数量。 --lr: 初始学习率。 --imgsz: 输入图像尺寸(640x640,需与导出和推理尺寸一致)。 3.2.6`numactl --cpunodebind=$numa_id --membind=$numa_id python3 export.py --imgsz 640 --opset 9 --weights runs/train/exp/weights/best.pt --include onnx --data /dataset/data.yaml --device cpu --export_kneron;cp runs/train/exp/weights/best.onnx runs/train/exp/weights/best_kneron.onnx;` 生成 Kneron 芯片专用的 ONNX 模型。 --opset: ONNX 算子集版本(opset=9 适配AMC芯片的算子兼容性)。 --device: 指定导出设备。 --export_kneron: 启用 AMC 专用优化。 3.2.7`numactl --cpunodebind=$numa_id --membind=$numa_id python3 export.py --imgsz 640 --weights runs/train/exp/weights/best.pt --include torchscript --device cpu;cd ..;mv yolov5/runs/train/exp/weights/best.torchscript yolov5/runs/train/exp/weights/best.torchscript.pt;` 生成 TorchScript 模型用于 PyTorch 生态部署。 --include: 指定导出格式(torchscript 生成 .torchscript 文件)。 --imgsz: 必须与训练时一致,否则模型输入形状不匹配。 3.2.8`torch-model-archiver --model-name best --version 1.0 --serialized-file yolov5/runs/train/exp/weights/best.torchscript.pt --handler yolov5_model_handler.py --extra-files /dataset/data.yaml,yolov5/runs/train/exp/weights/best.onnx;` 创建 TorchServe 可部署的模型存档。 --model-name: 模型名称(用于 TorchServe 的 API 路径)。 --serialized-file: 序列化模型文件(TorchScript 或 PyTorch 模型)。 --handler: 自定义请求处理器(定义数据预处理/后处理逻辑)。 --extra-files: 附加文件(数据集配置 data.yaml 和 ONNX 模型备用)。 3.2.9`cp /code/yolov5/runs/train/exp/weights/* /model/;cp /dataset/data.yaml /model/;cp /code/best.mar /model/` 统一复制所有生成文件到 /model 目录,包含:训练权重、ONNX 模型、TorchScript 模型、MAR 存档、配置文件。
gdsoke
2025年5月28日 11:17
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码