AI CT平台使用手册
自动驾驶算法开发创新挑战赛
本文档使用 MrDoc 发布
-
+
首页
自动驾驶算法开发创新挑战赛
## 1. 平台登录 学生输入竞赛平台网址,进行登录操作。 竞赛地址与账号密码会于比赛前给出。  学生进入平台后,进入个人信息界面,选择团队成员。 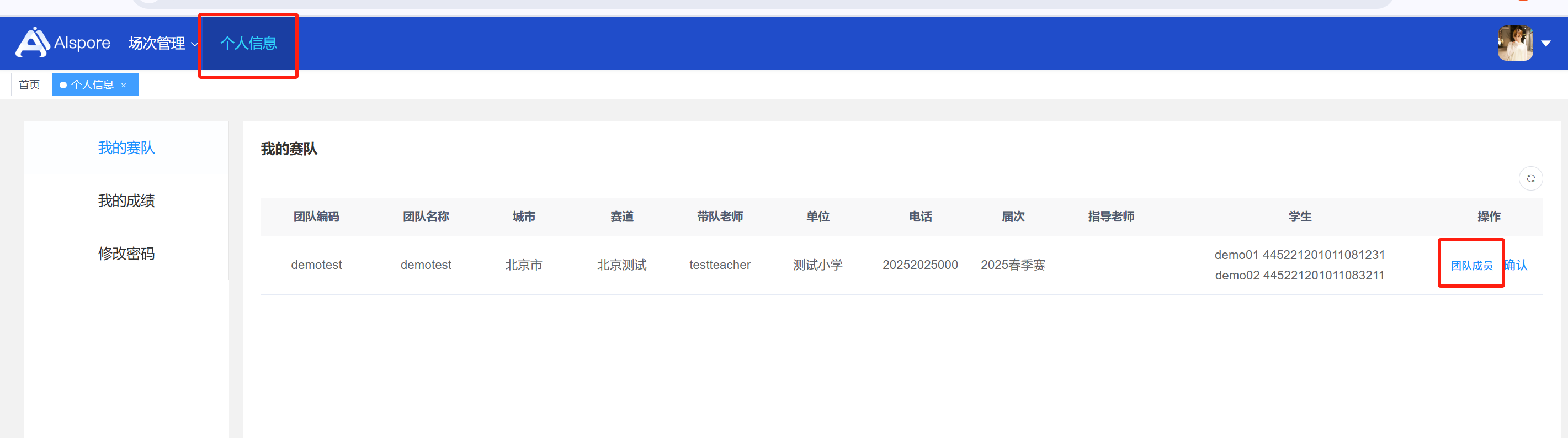 点击修改按钮进行信息确认和人像上传。 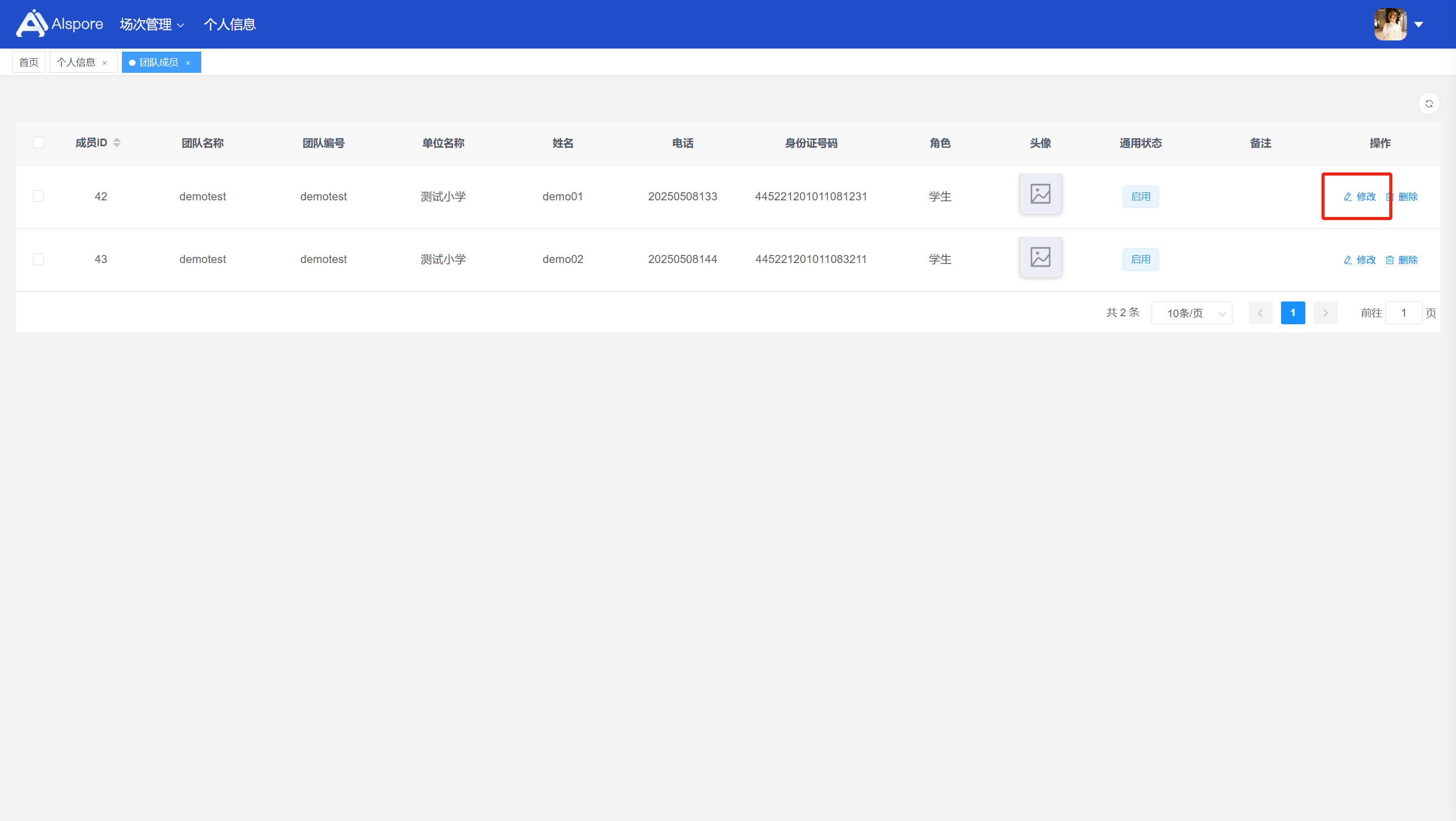 确认信息无误后点击下一步 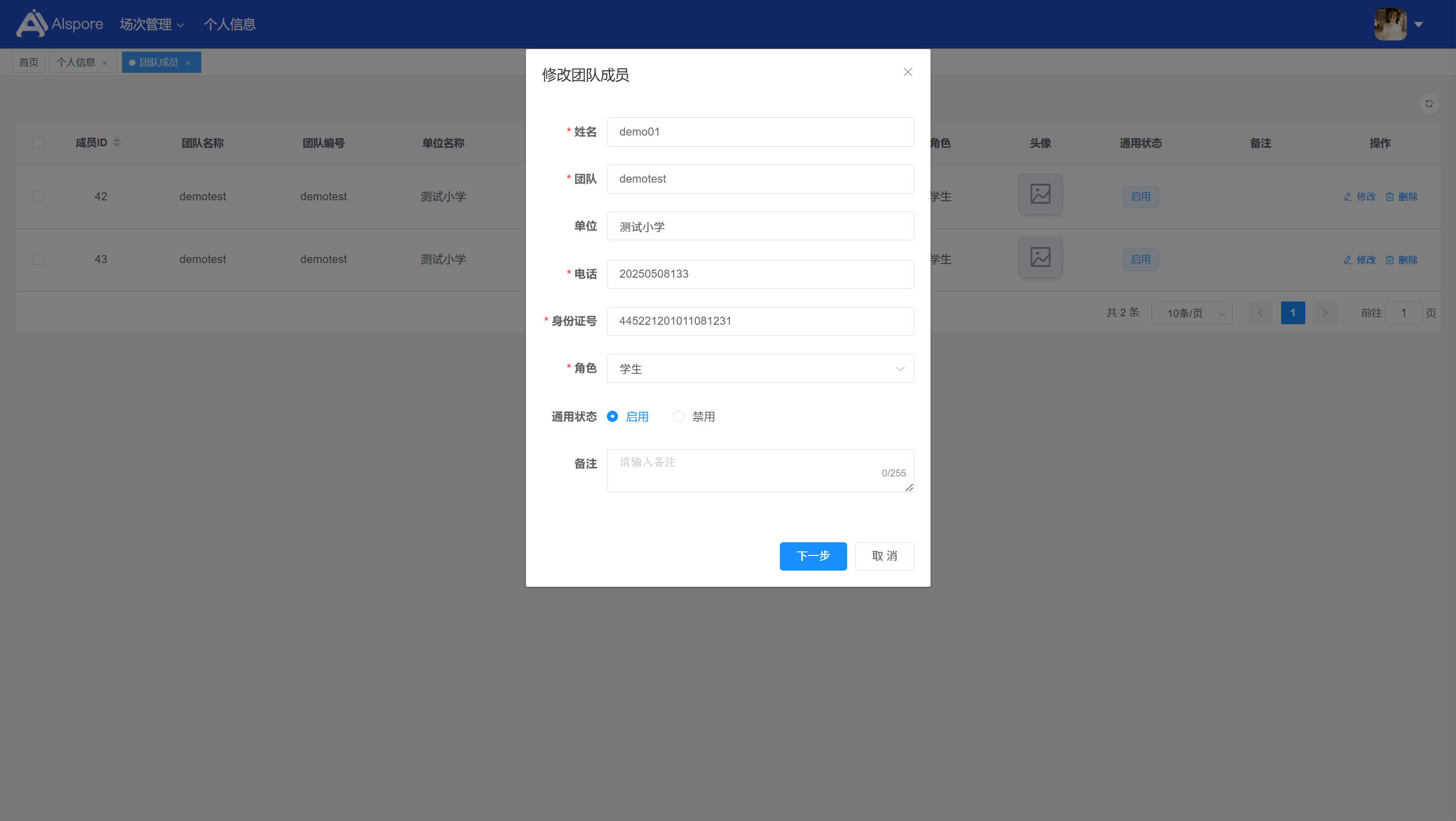 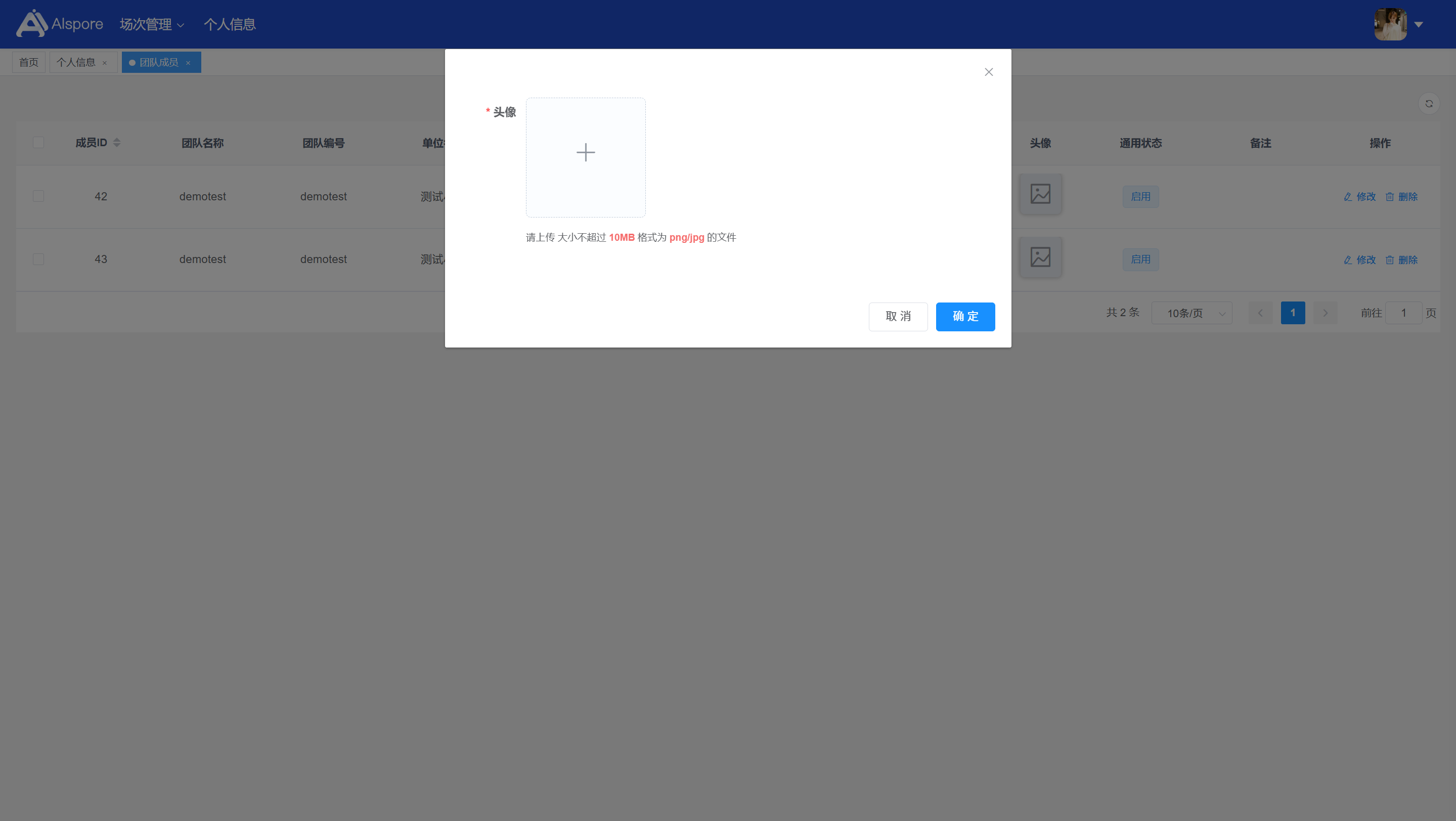 当个人信息与人像上传都操作完毕后,即可回到个人信息界面进行确认。 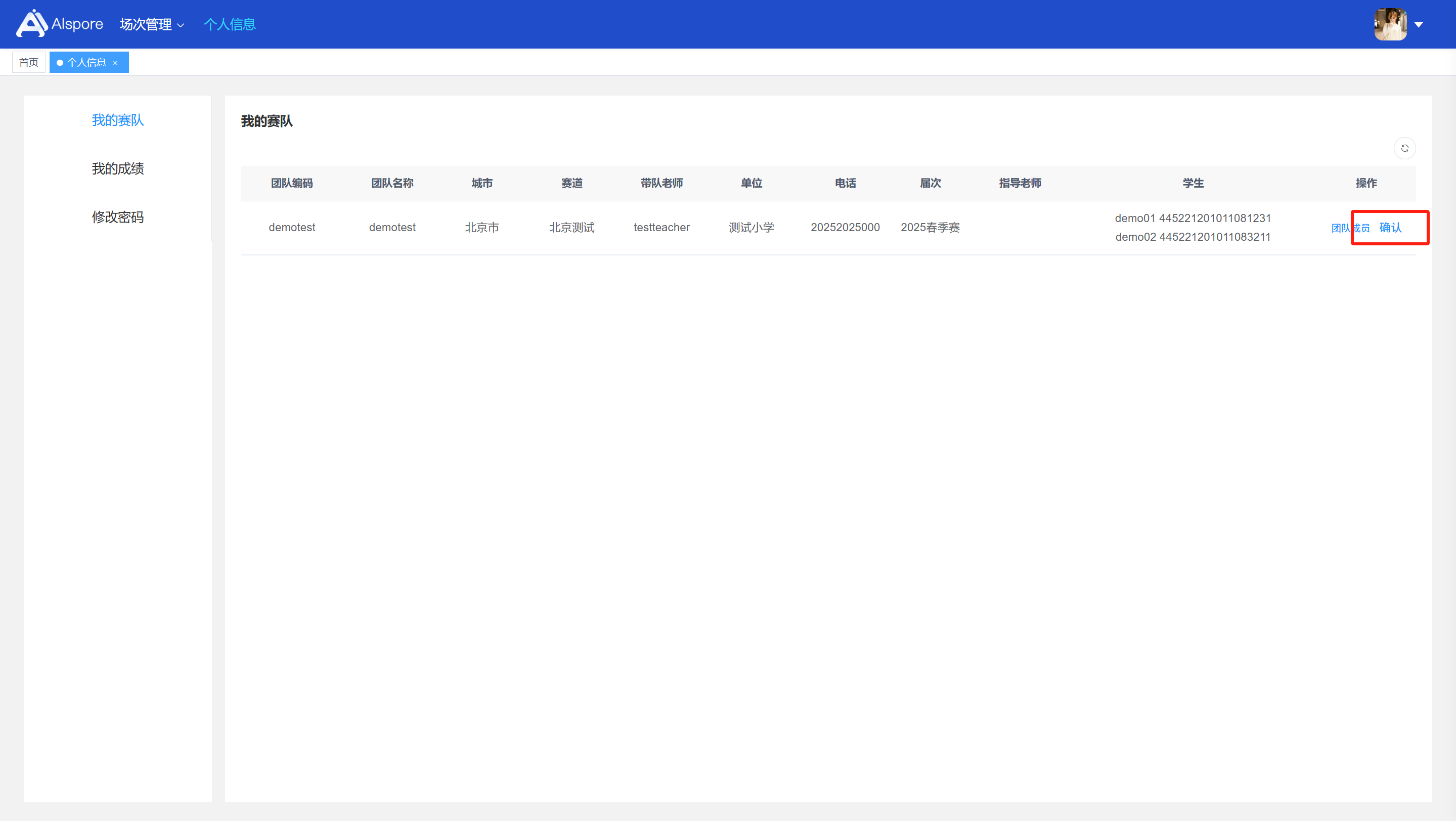 学生回到场次管理中的团队场次列表,可以看到状态显示为比赛中,此时点击去编程 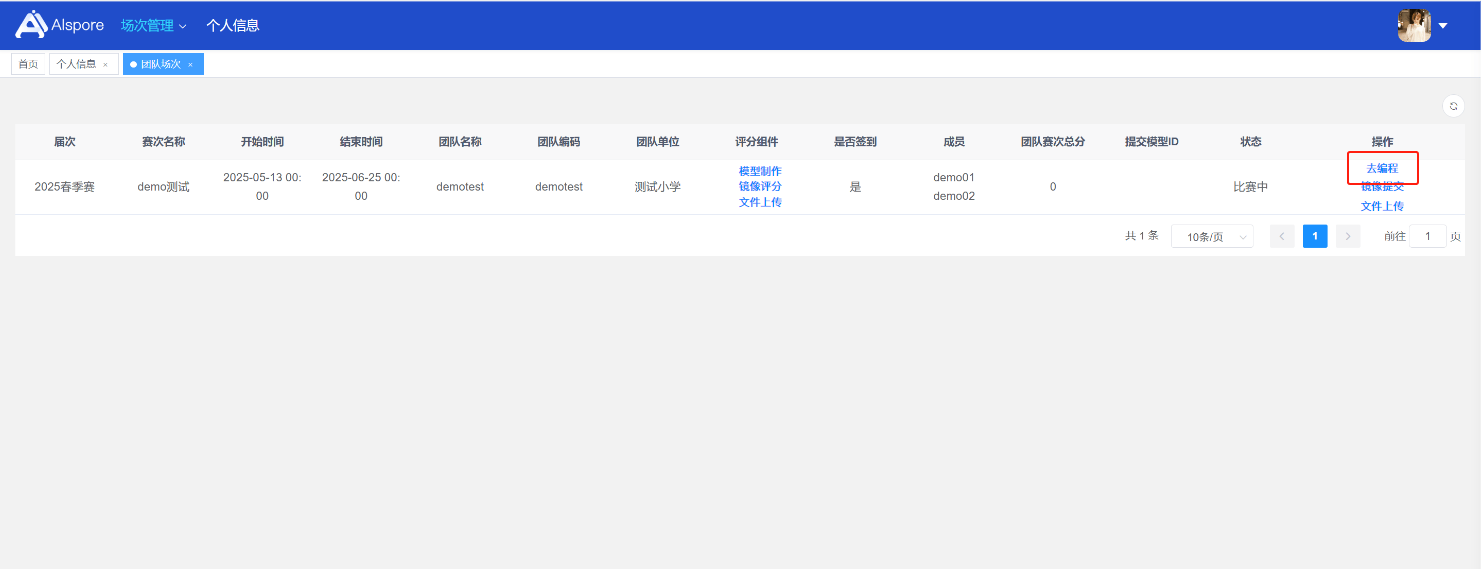 然后会跳转到AI工作坊比赛平台  ## 2. 数据工程 ### 2.1 数据标注工具 数据标注工具可采用labelme软件进行数据标注(交通标志标注、车道线标注) 下载与使用教程如下: https://blog.csdn.net/CAUC_learner/article/details/99655776 ### 2.2 采集标注数据集 交通标志示例: 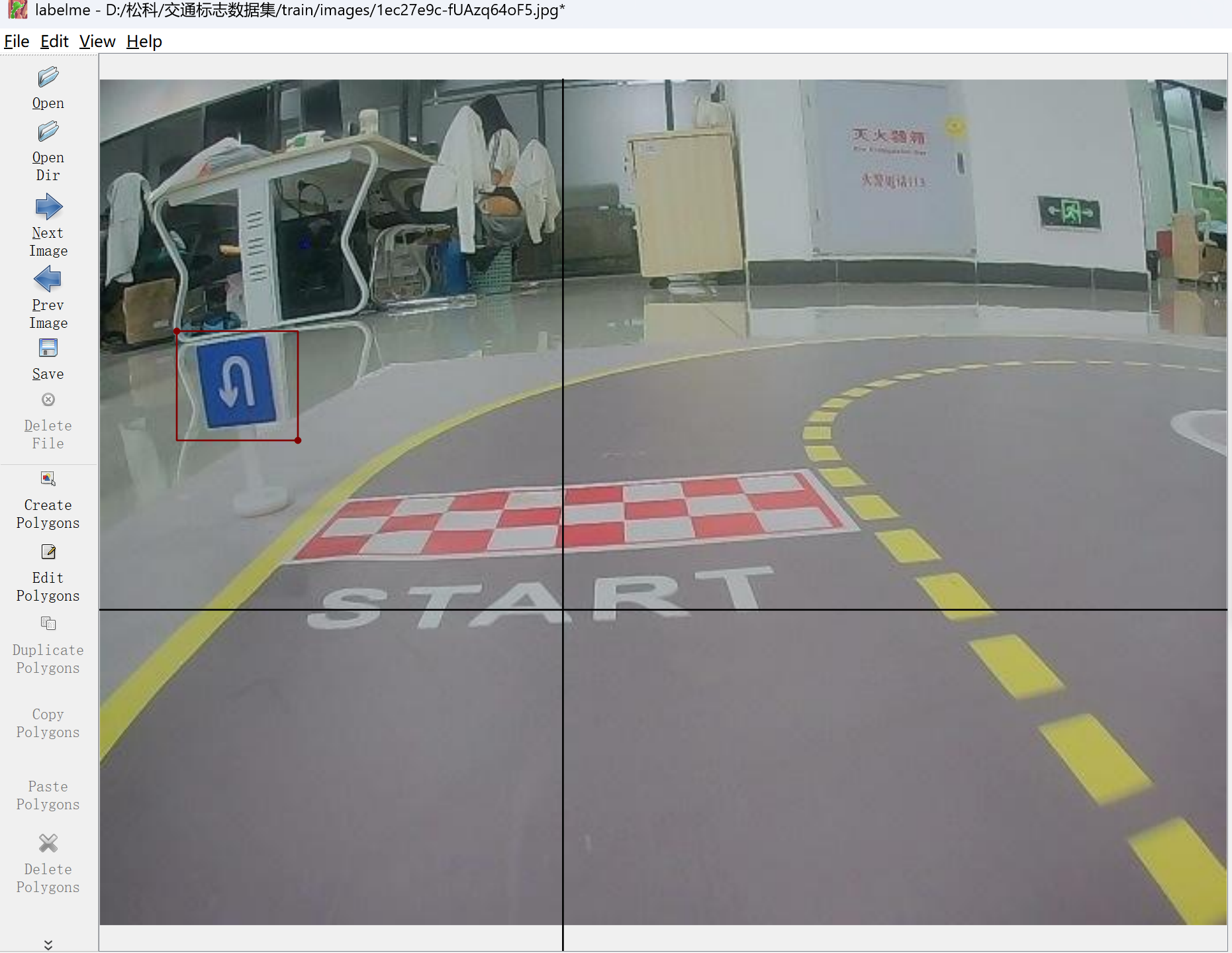 车道线示例: 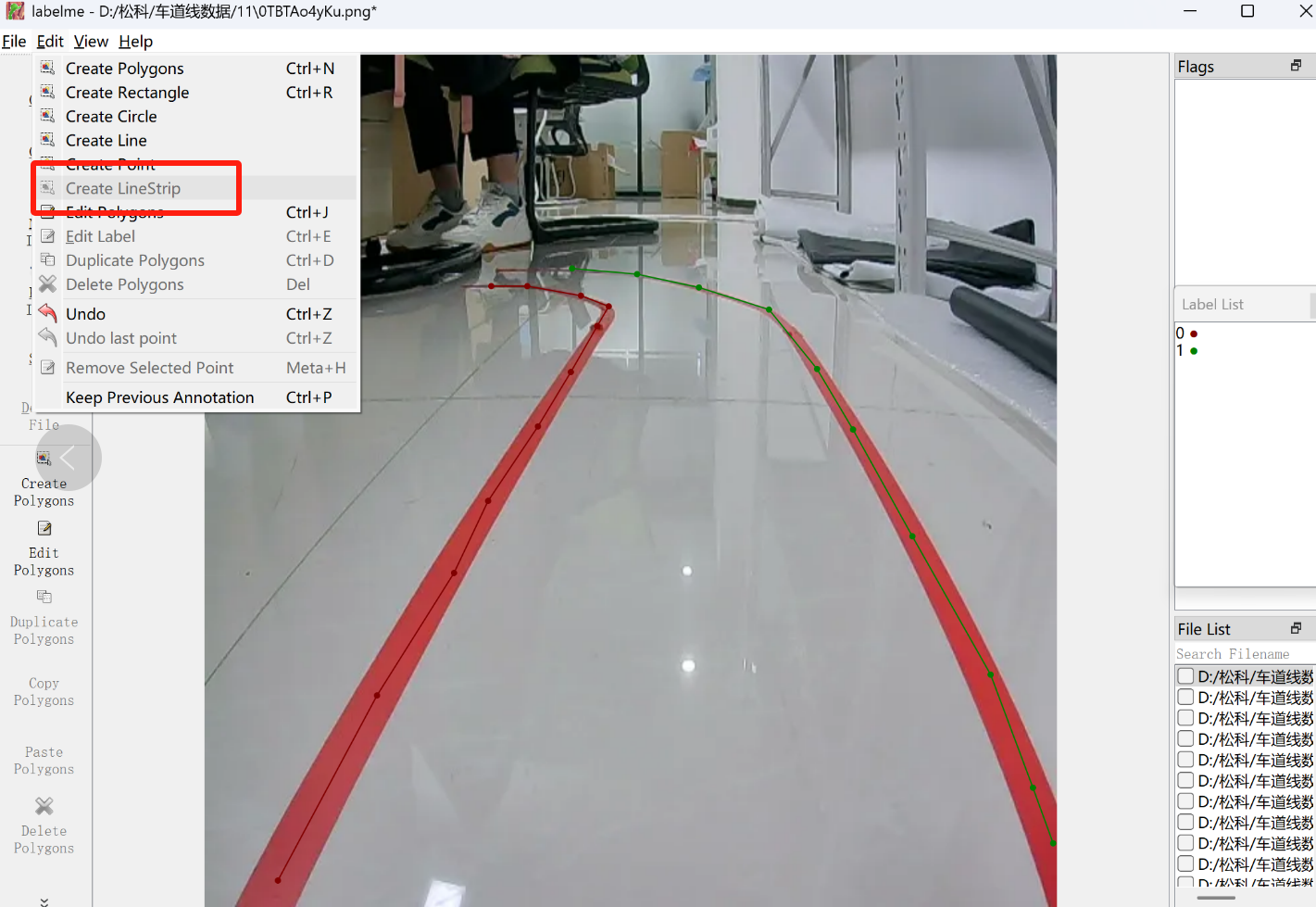 ### 2.3 上传完整数据集 当标注完成后下载导出数据集后,在AI工作坊比赛平台的数据管理目录下点击创建 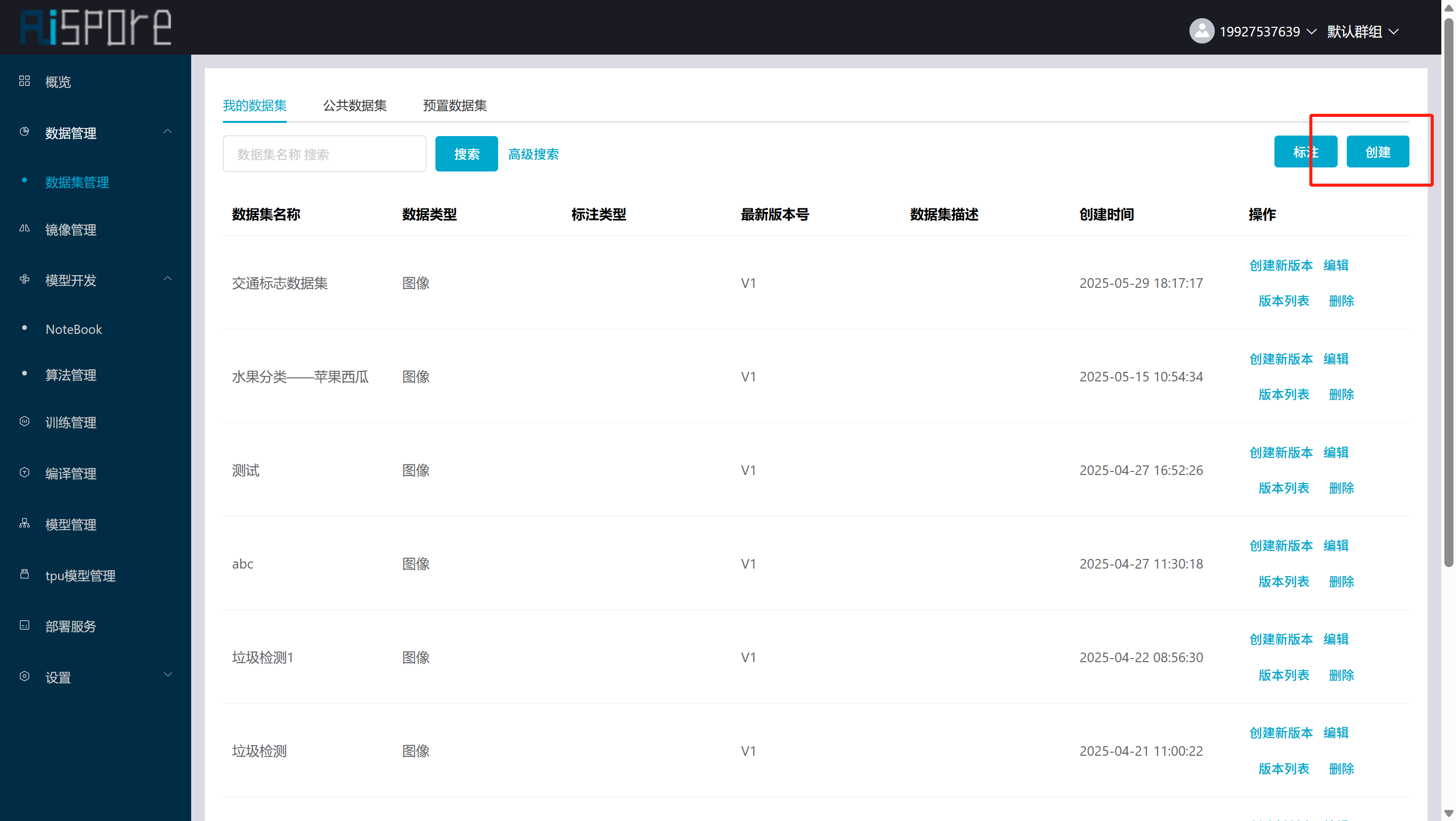 输入数据集信息后上传标注完成的数据集 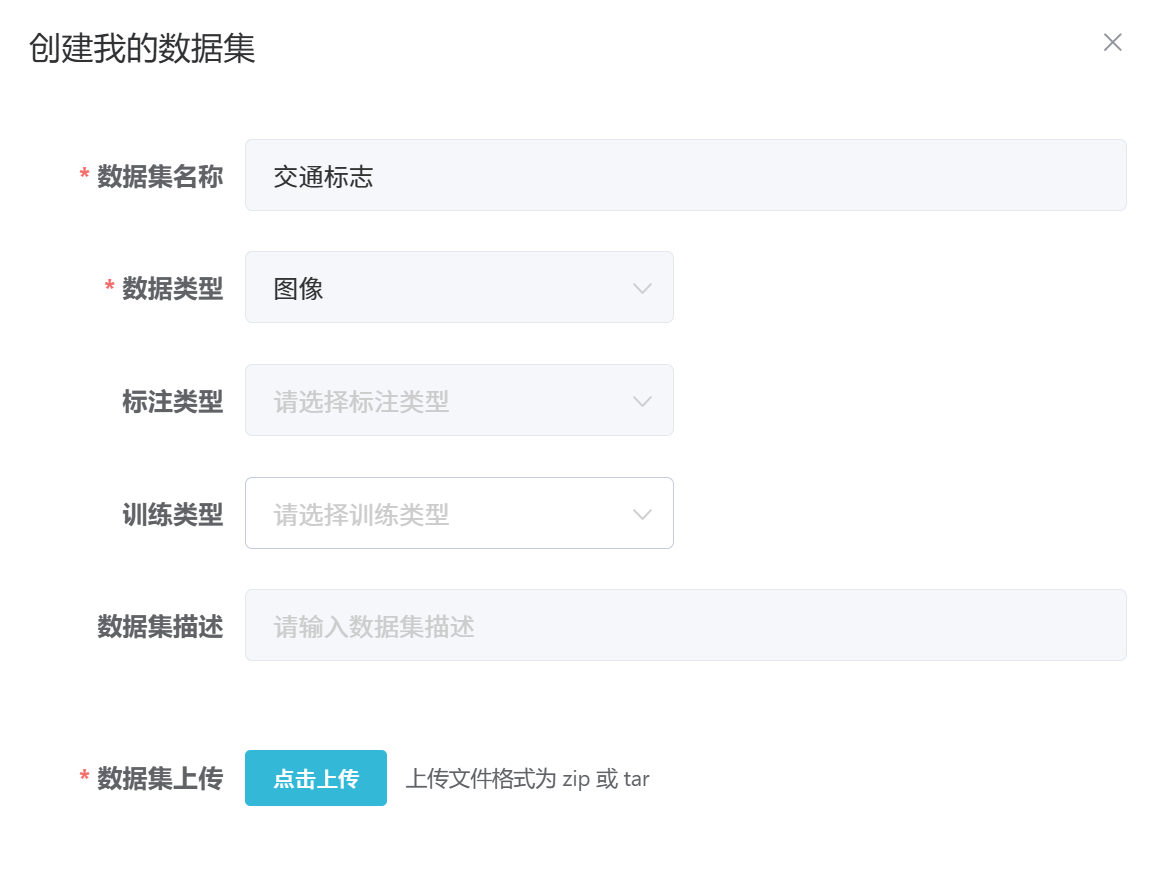 ## 3. 模型开发 ### 3.1 上传算法 选择【模型开发-算法管理】 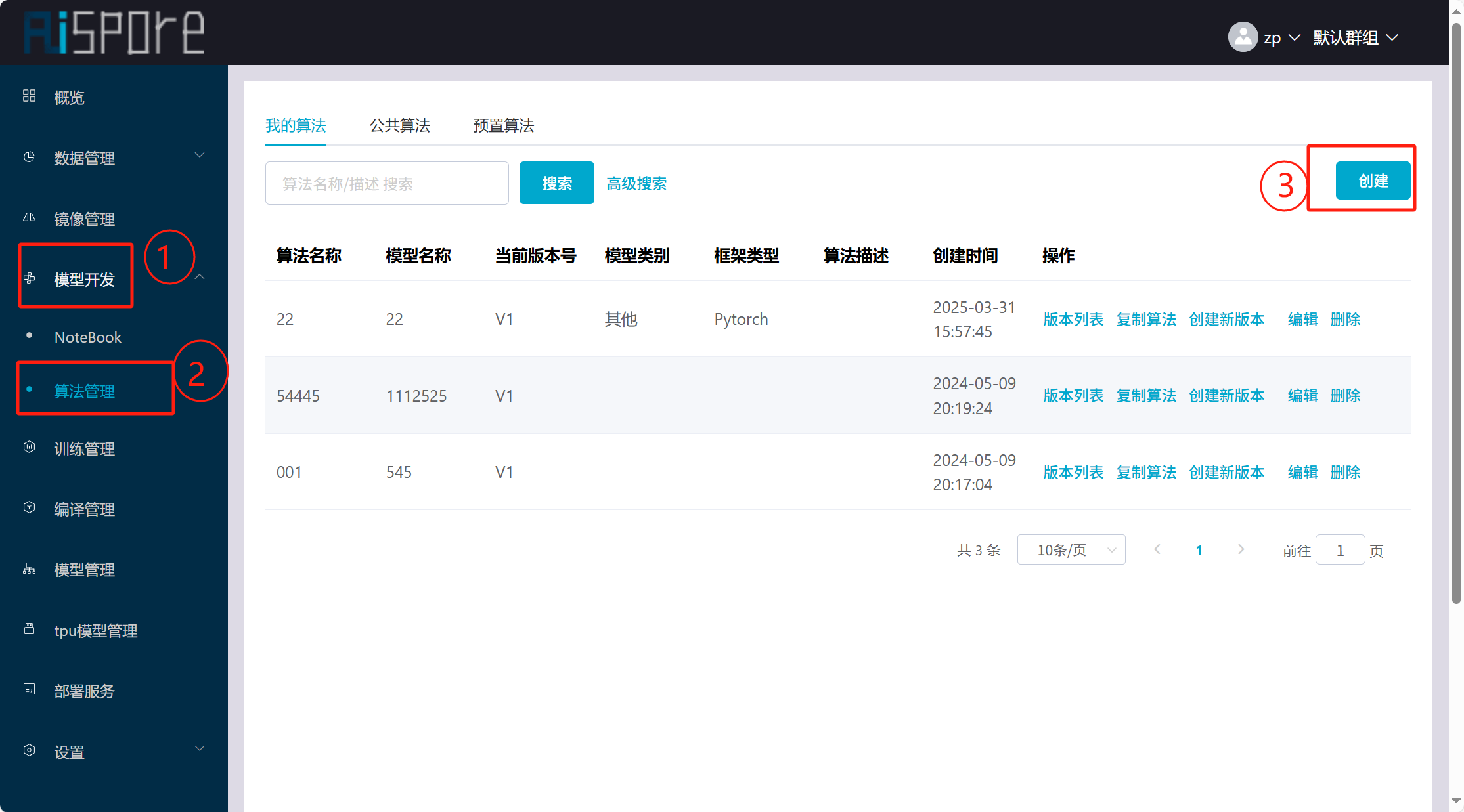 ### 3.2 创建容器 点击Notebook进行创建 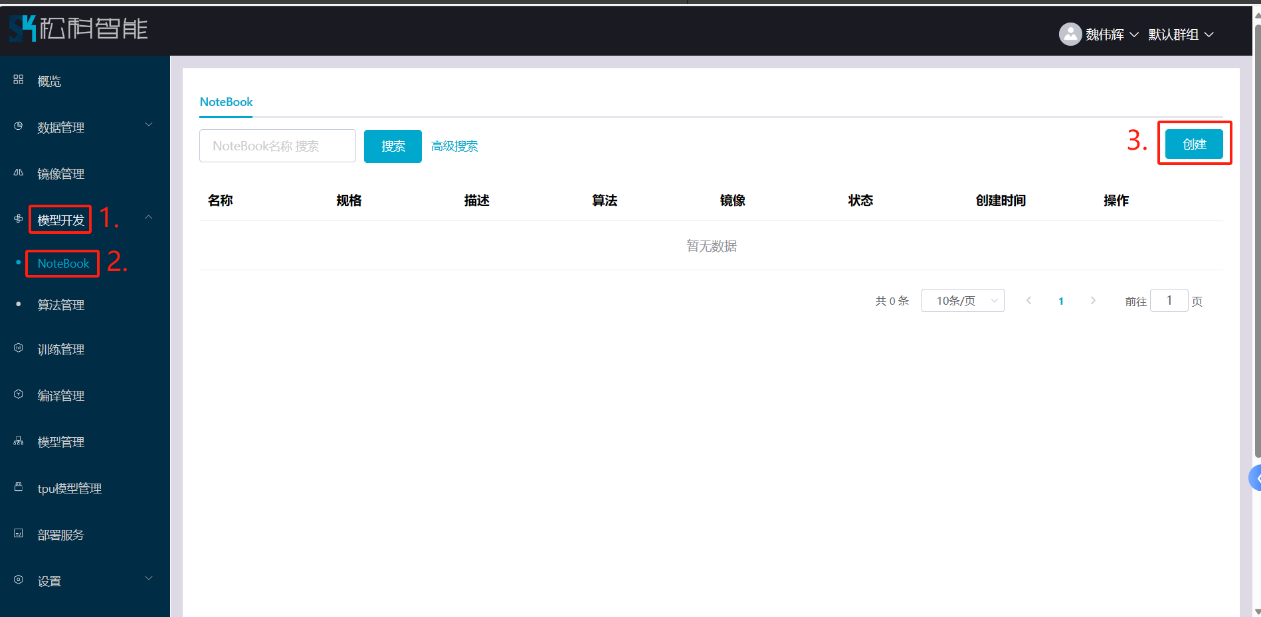 新建Notebook项目,选择自己的算法与预设镜像。 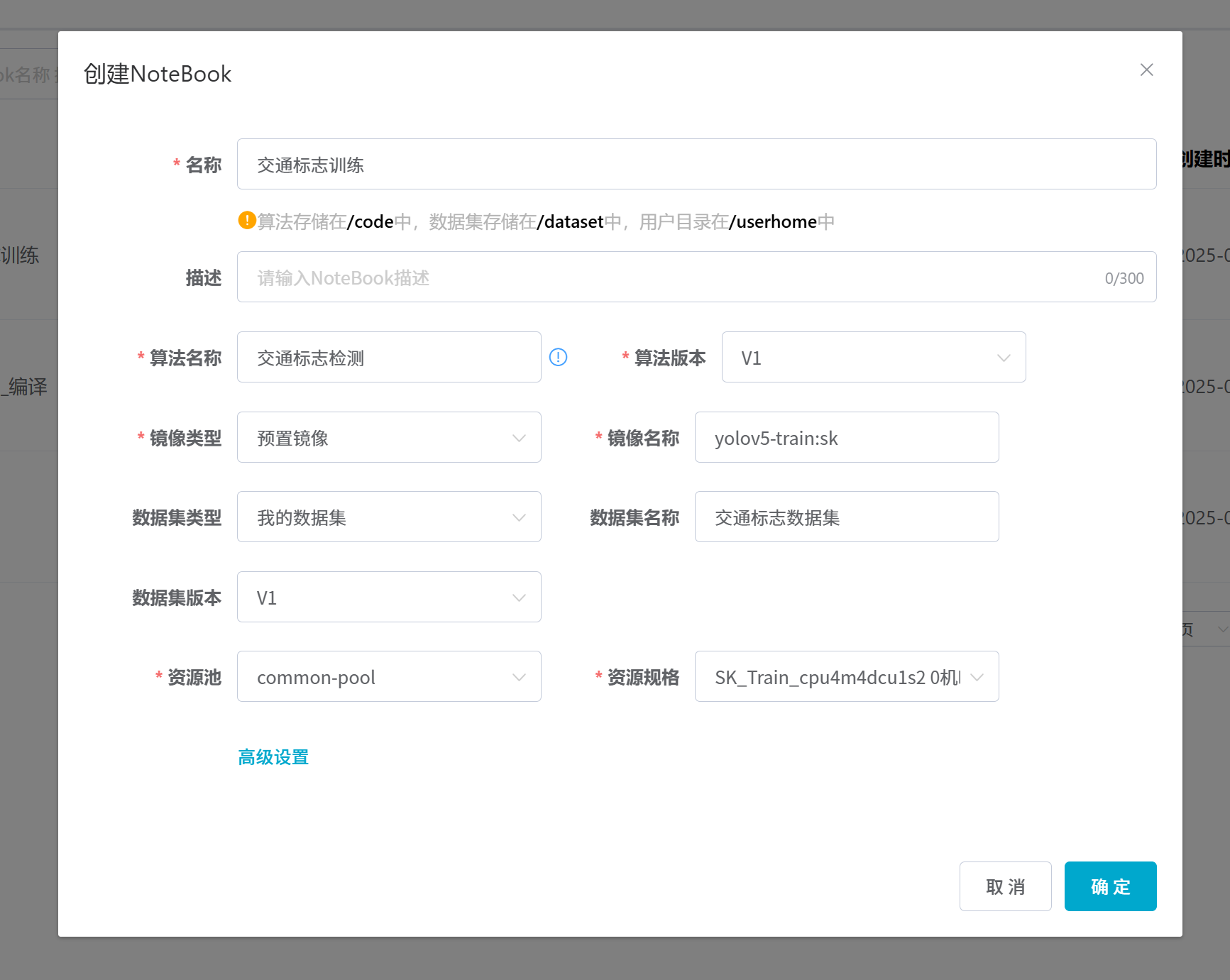 Note配置完成后点击确认,然后即可在NoteBook列表中看到刚刚创建的项目,点击打开  进入notebook编程界面 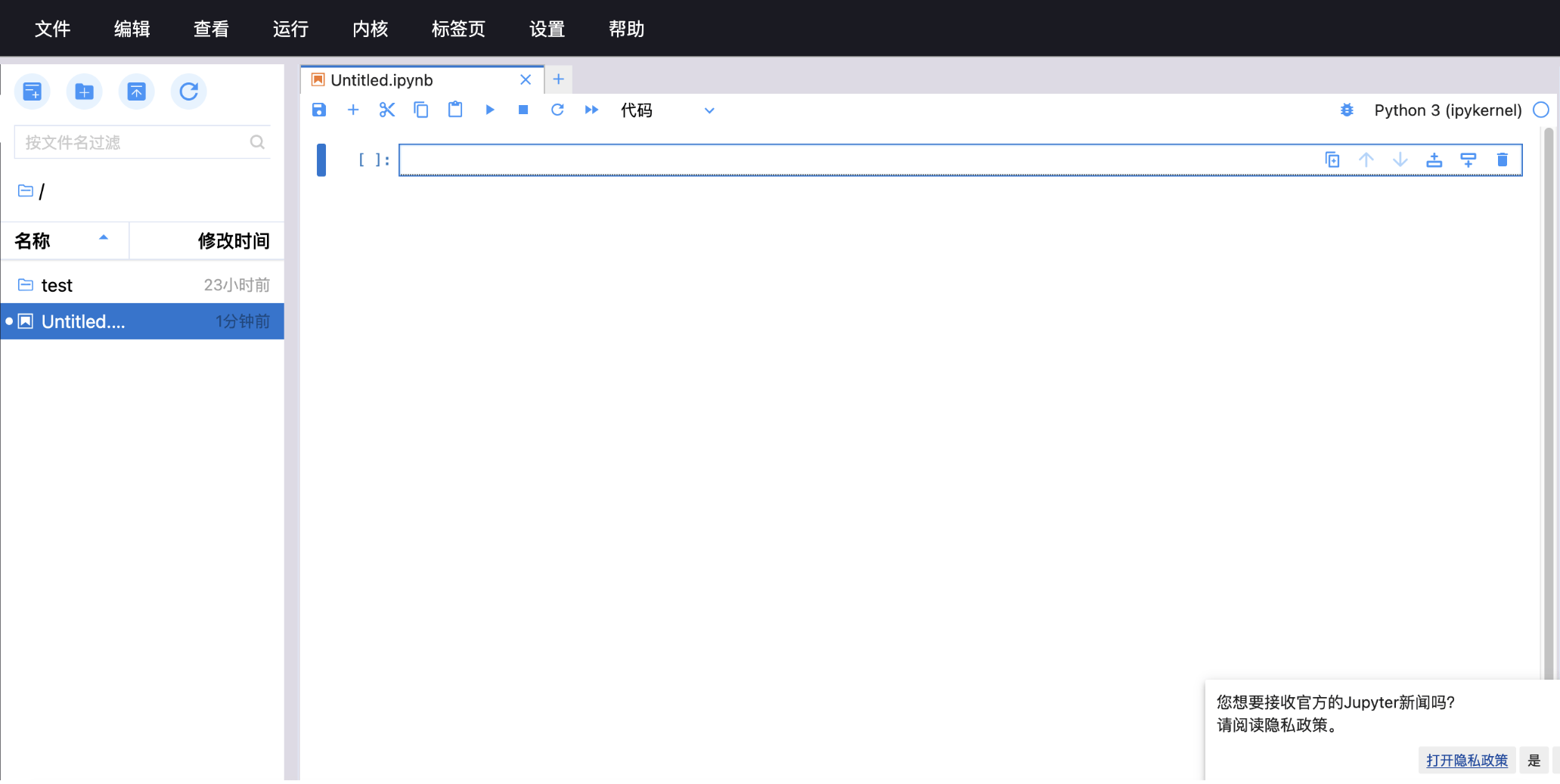 ### 3.3 训练模型 训练文件代码根据自己的需求进行编写,但在平台进行训练需要修改好数据集路径跟模型保存路径,以下操作为交通标志检测yolov5为例展示操作: 进入终端,找到我们的数据集,输入这些指令进行操作,数据集路径为(dataset,dataset/train ,dataset/val)  代码中设置数据集路径,点击yolov5  找到并进入train.py文件,查找红色方框内的代码,这是data的路径 (data/trash.yaml) 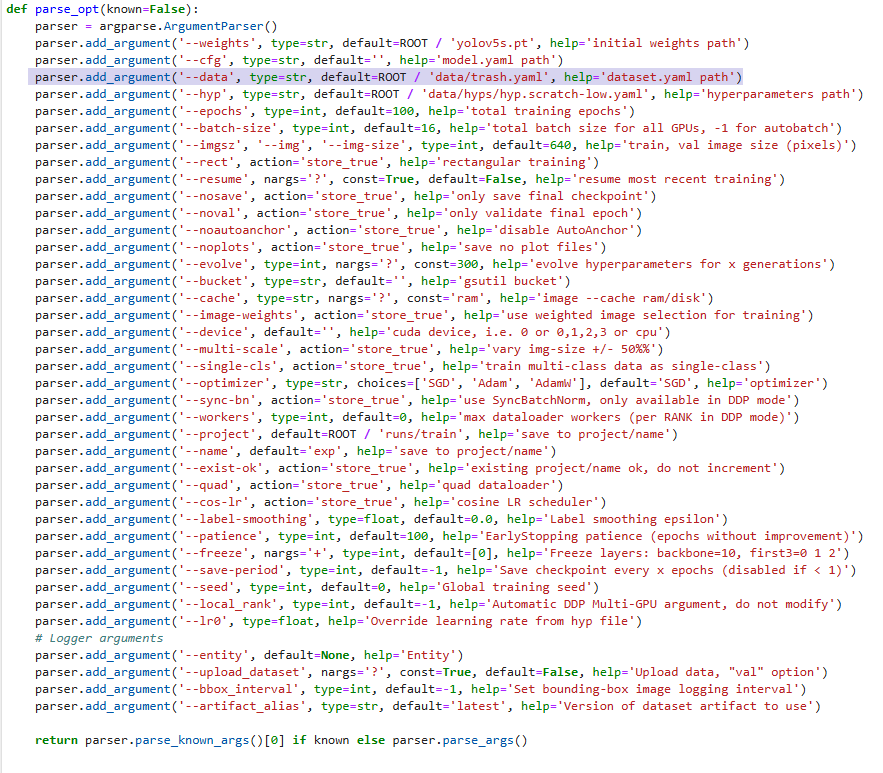 我们去data目录寻找trash.yaml文件 设置我们数据集的路径  找到之后修改我们的path train val的路径,把我们之前找到的数据集路径对照修改数据集路径为(dataset,dataset/train ,dataset/val)  修改完数据集的路径后,再修改我们标签名classes  回到终端,进入code目录,再进入yolov5目录下进行训练 命令行指令为: ```python cd code #进入code目录 cd yolov5 #进入yolov5目录 python train.py --epochs 1 --batch-size 8 --imgsz 256 #其中Epochs是训练次数、Batch是一次获取多少张图片、Imgsz是图片像素大小 ``` 出现以下代码表示训练成功而且已完成,训练好的模型存在红色的方框内 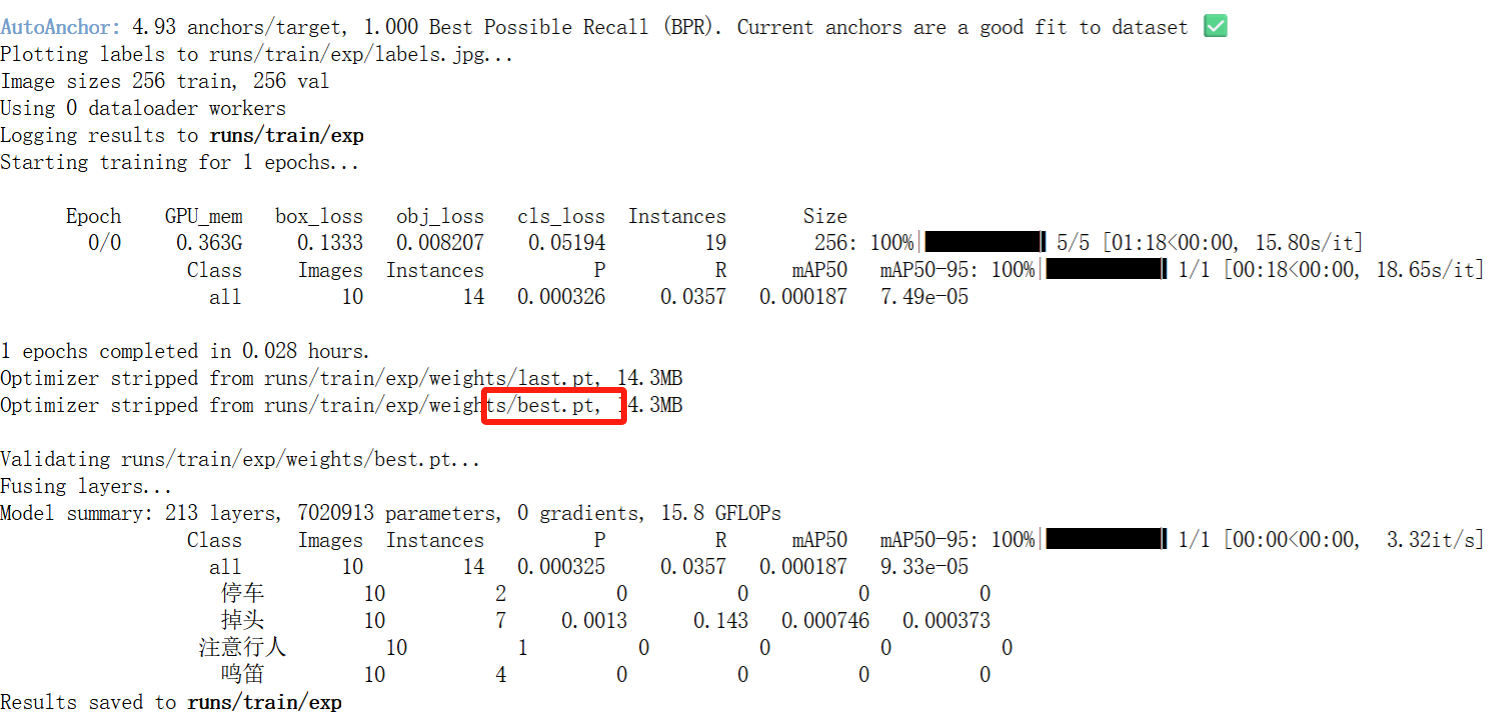 ### 3.4 导出onnx 终端进入yolov5目录中,将刚刚训练得到的模型文件:pt文件转为onnx文件,代码如下: ```python cd code/yolov5 python export.py --imgsz 640 --opset 12 --weights runs/train/exp/weights/best.pt --include onnx --data /dataset/data.yaml --device 0 --export_tpu ``` (其中imgsz指输入图像尺寸、opset指ONNX算子集版本、weights指训练好的模型权重路径、include指导出格式为ONNX、data指数据集路径、device指使用的设备为GPU或CPU、--export_tpu指针对TPU1000芯片的特殊导出模式) ```python cd .. cp /code/yolov5/runs/train/exp/weights/* /model/ cp /dataset/data.yaml /model/ ``` (将模型文件(best.pt、best.onnx)和数据集配置(data.yaml)复制到 /model 目录) ### 3.5 推理验证 接下来参考附件内容编写模型处理文件(预处理、后处理等) 此处以yolov5为例,详细代码可查看附件,将附件中的模型处理文件Predictor.py移入/code目录下。[【附件】Predictor.zip](/media/attachment/2025/05/Predictor.zip) #### 注意: ==1.模型处理文件命名统一为:Predictor.py 2.模型处理文件中的类名统一为:class Predictor() 3.模型推理输出格式统一为:[x,y,w,h,score,class] 推理输出格式可在附件Predictor.py代码中查看== 推理代码如下: ```python python Predictor.py --weights runs/train/exp/weights/best.pt --source /dataset/images ```  推理结果存放在红色方框内的路径 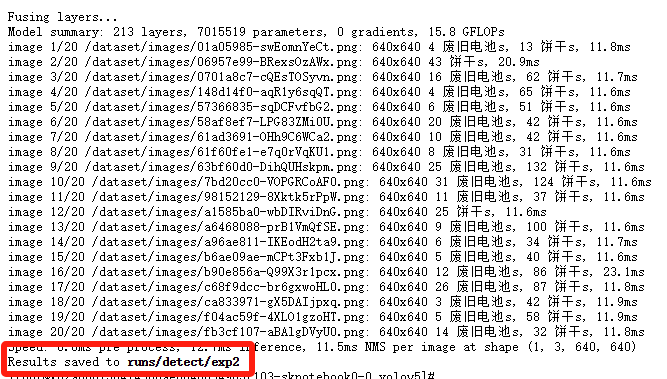 最后可以去文件夹查看推理结果  重要:编写调试完成后,将==模型文件xxxx.onnx==、==数据集配置data.yaml==、==模型处理文件Predictor.py==以及==所需依赖requirements.txt==,四个文件直接打包zip格式(压缩包中直接放文件,没有文件夹),后续用于在竞赛平台提交评分。 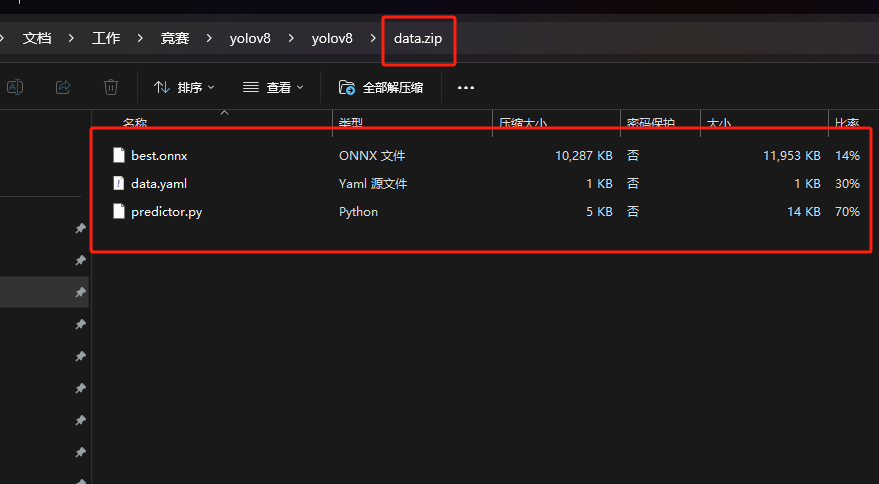 ## 4 编译模型 将pt转换为ONNX格式完成后,用户返回竞赛平台NoteBook界面,创建一个用于编译的NoteBook项目 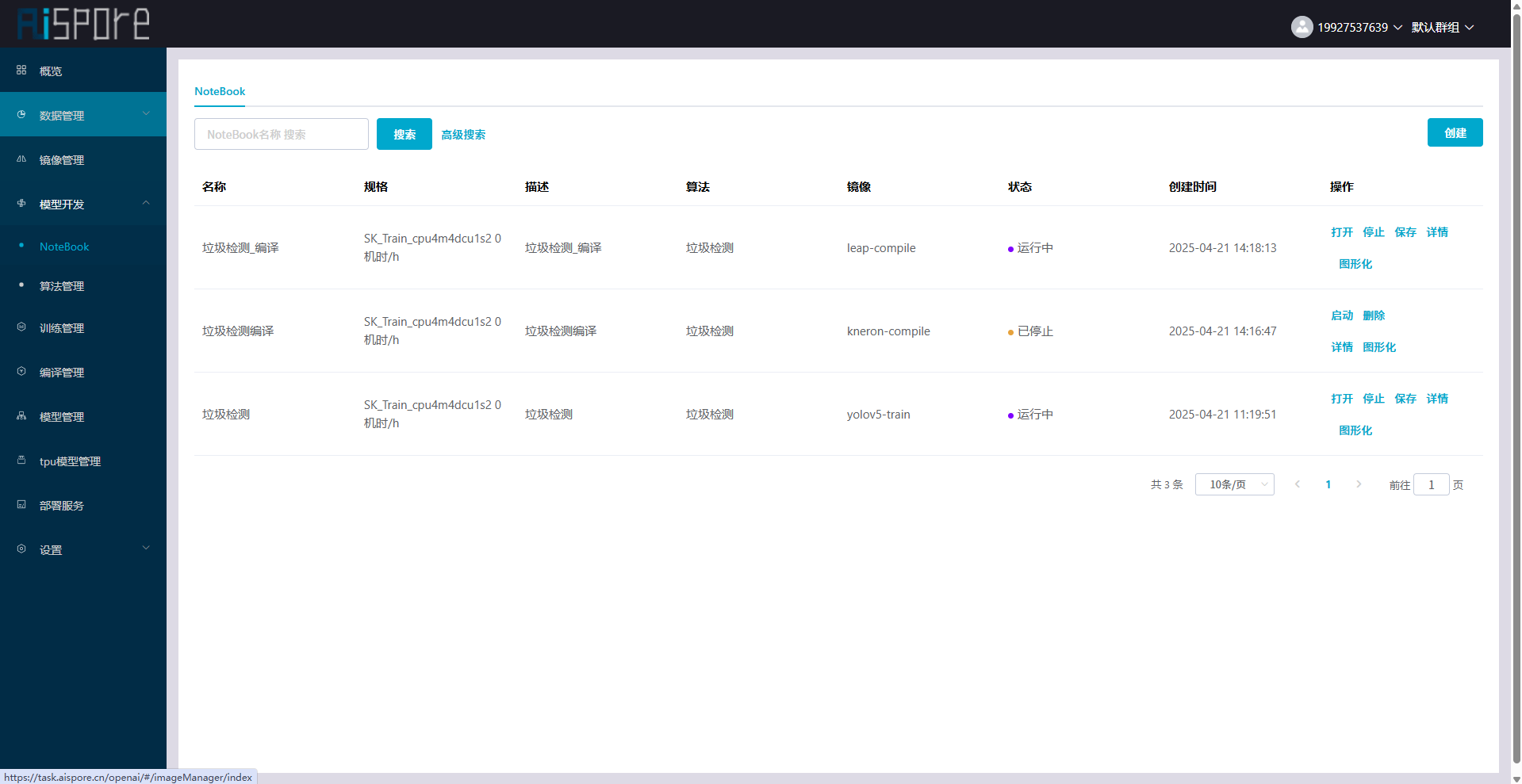 创建编译的notebook项目 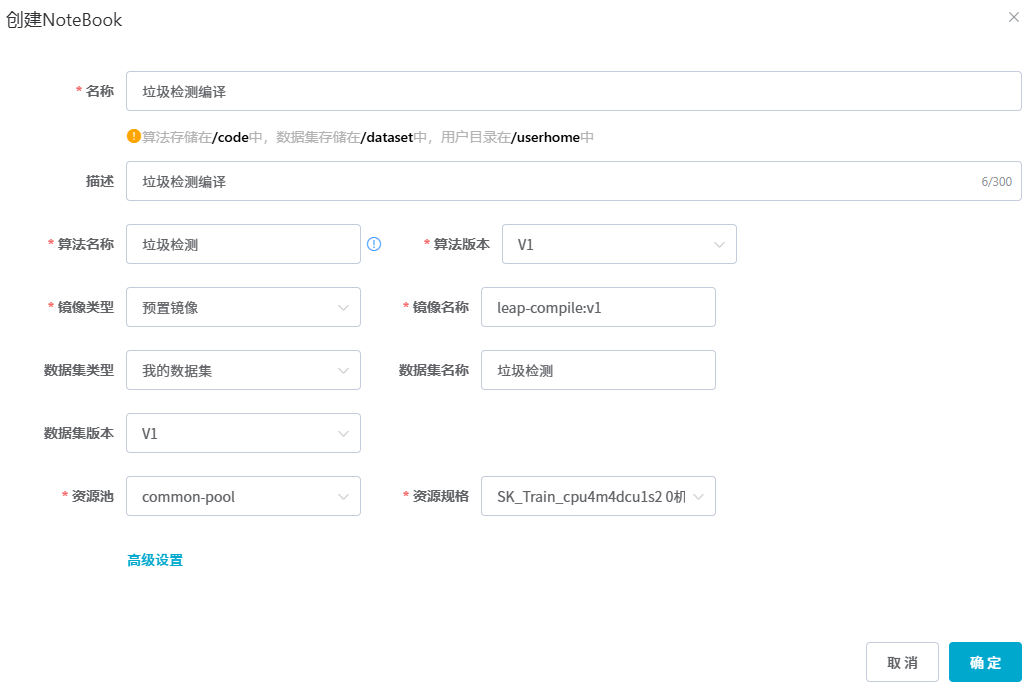 打开编译的notebook项目(区别于前面用于训练的notebook) 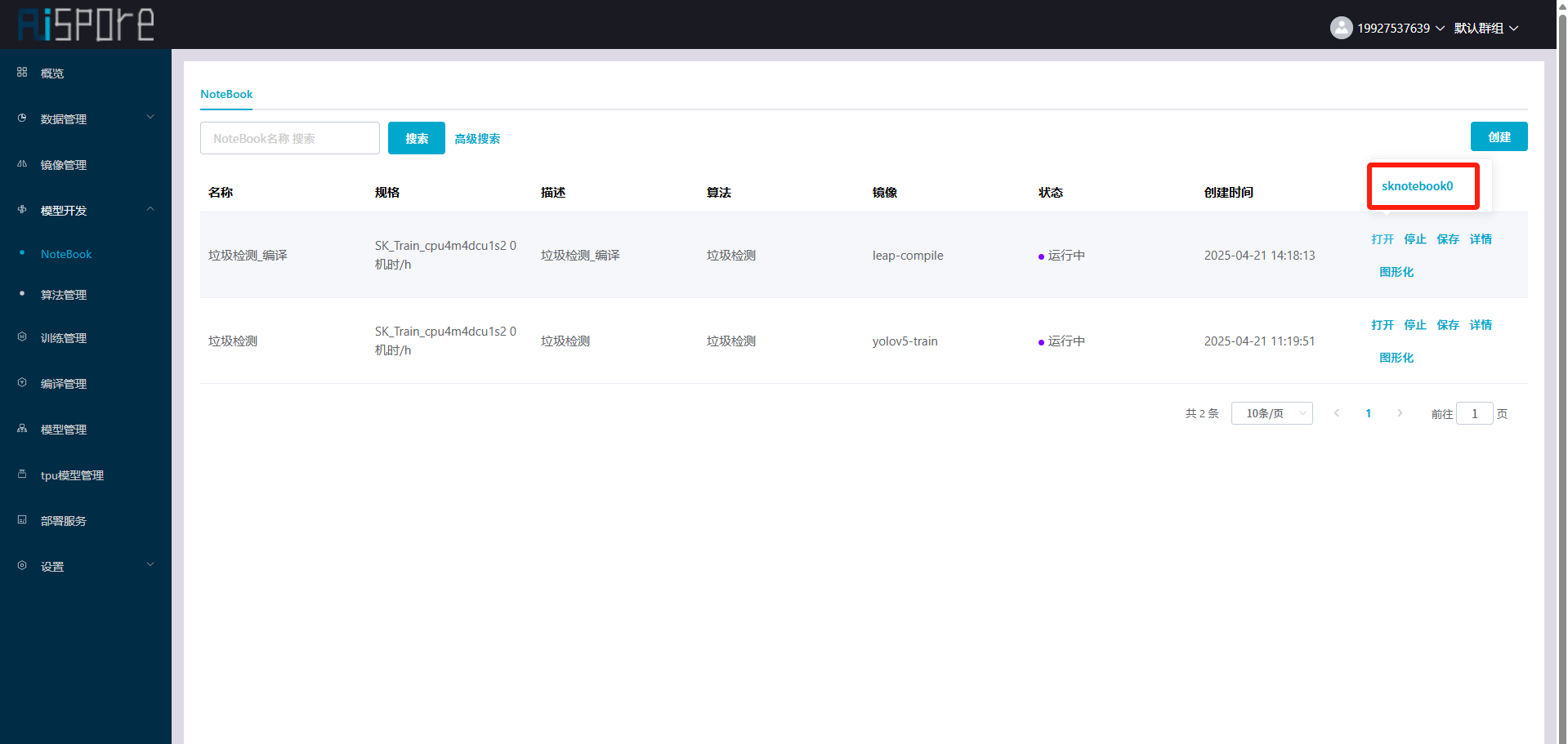 运行编译,代码如下: ```python find /dataset -name "*.jpg" -o -name "*.png" -o -name "*.jpeg" -o -name "*.JPG" -o -name "*.PNG" -o -name "*.JPEG"| shuf -n 100 | xargs -I {} cp {} /datasets/ILSVRC2012/ILSVRC2012_img_val&&cd /detvm&&python3 example.py --model_input1_path=$( find /datasets/ILSVRC2012/ILSVRC2012_img_val/ -type f -name "*.jpg" -o -name "*.png" -o -name "*.jpeg" -o -name "*.JPG" -o -name "*.PNG" -o -name "*.JPEG"| shuf -n 1) --model_input1_name=images --model_input1_shape3=640 --model_input1_shape4=640 --quantize_mean1=0.0 --quantize_mean2=0.0 --quantize_mean3=0.0 --quantize_scale1=255.0 --quantize_scale2=255.0 --quantize_scale3=255.0 --quantize_prof_img_num=0 {sk-param}&&mv /DEngine/model/dp1000/onnx_squeezenet_v1.1/net.bin /tpumodel/&&mv /DEngine/model/dp1000/onnx_squeezenet_v1.1/model.bin /tpumodel/&&cp /model/data.yaml /tpumodel/ ``` 此为多段命令组合,具体含义分解如下: ```python find /dataset -name "*.jpg" -o -name "*.png" -o -name "*.jpeg" -o -name "*.JPG" -o -name "*.PNG" -o -name "*.JPEG"| shuf -n 100 | xargs -I {} cp {} /datasets/ILSVRC2012/ILSVRC2012_img_val ``` 从 /dataset 随机抽取100张图片到目标目录(格式兼容 JPG/PNG 等) ```python cd /detvm python3 example.py --model_input1_path=$( find /datasets/ILSVRC2012/ILSVRC2012_img_val/ -type f -name "*.jpg" -o -name "*.png" -o -name "*.jpeg" -o -name "*.JPG" -o -name "*.PNG" -o -name "*.JPEG"| shuf -n 1) --model_input1_name=images --model_input1_shape3=640 --model_input1_shape4=640 --quantize_mean1=0.0 --quantize_mean2=0.0 --quantize_mean3=0.0 --quantize_scale1=255.0 --quantize_scale2=255.0 --quantize_scale3=255.0 --quantize_prof_img_num=0 {sk-param} ``` 这里执行编译脚本example.py,指定输入参数(模型路径、输入尺寸、量化参数等) ```python mv /DEngine/model/dp1000/onnx_squeezenet_v1.1/net.bin /tpumodel/ ``` 将编译生成的二进制文件 net.bin 移动到 /tpumodel 目录 ```python mv /DEngine/model/dp1000/onnx_squeezenet_v1.1/model.bin /tpumodel/ ``` 将编译生成的二进制文件 model.bin 移动到 /tpumodel 目录 ```python cp /model/data.yaml /tpumodel/ ``` 复制配置文件 data.yaml ## 5. 部署验证 进入tpumodel目录将编译好的net.bin文件、model.bin文件和yaml文件下载到本地并放到一个文件夹中,压缩为ZIP文件  在TPU模型管理菜单下,创建tpu模型 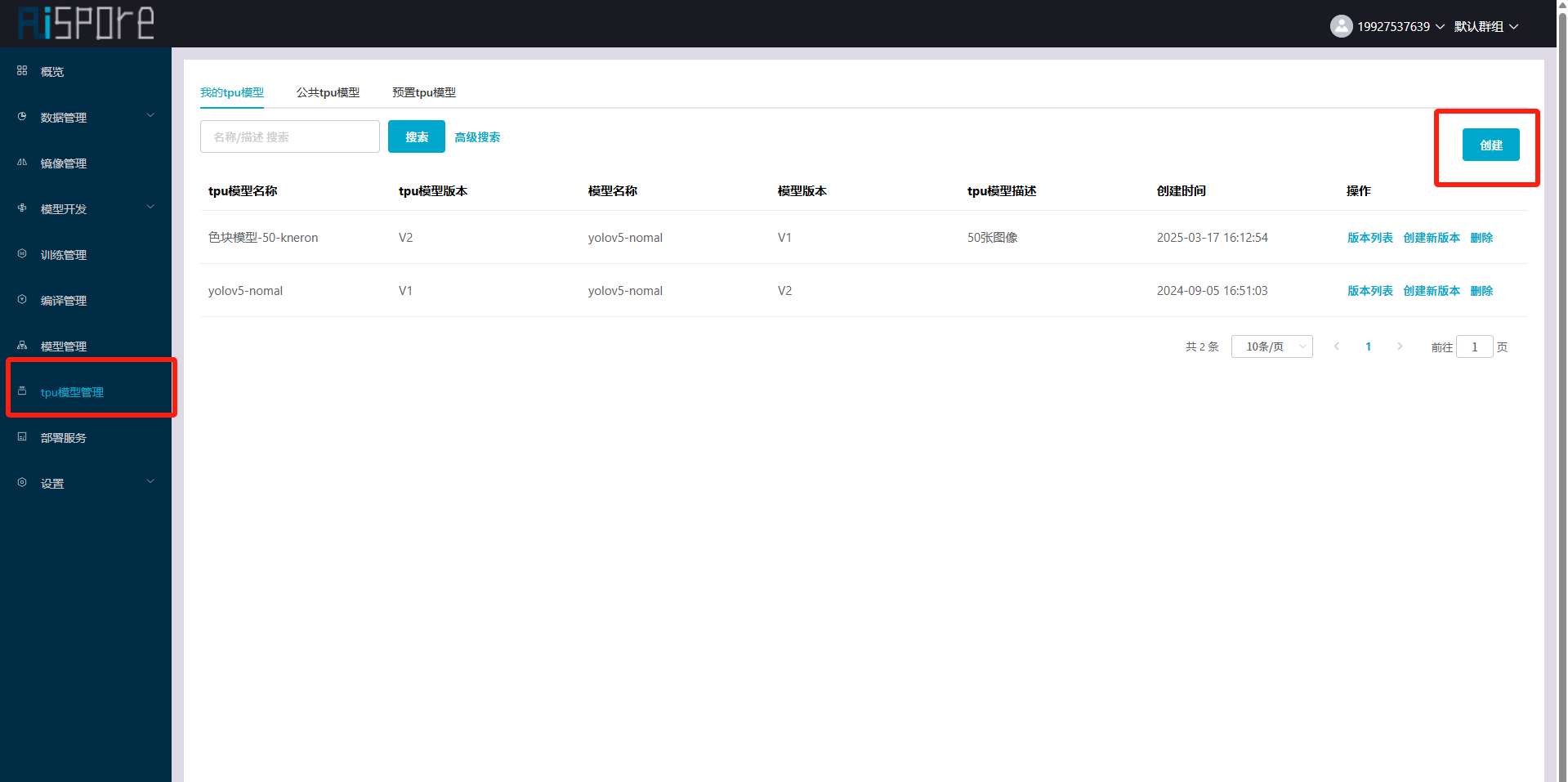 输入信息并上传tpu模型压缩包 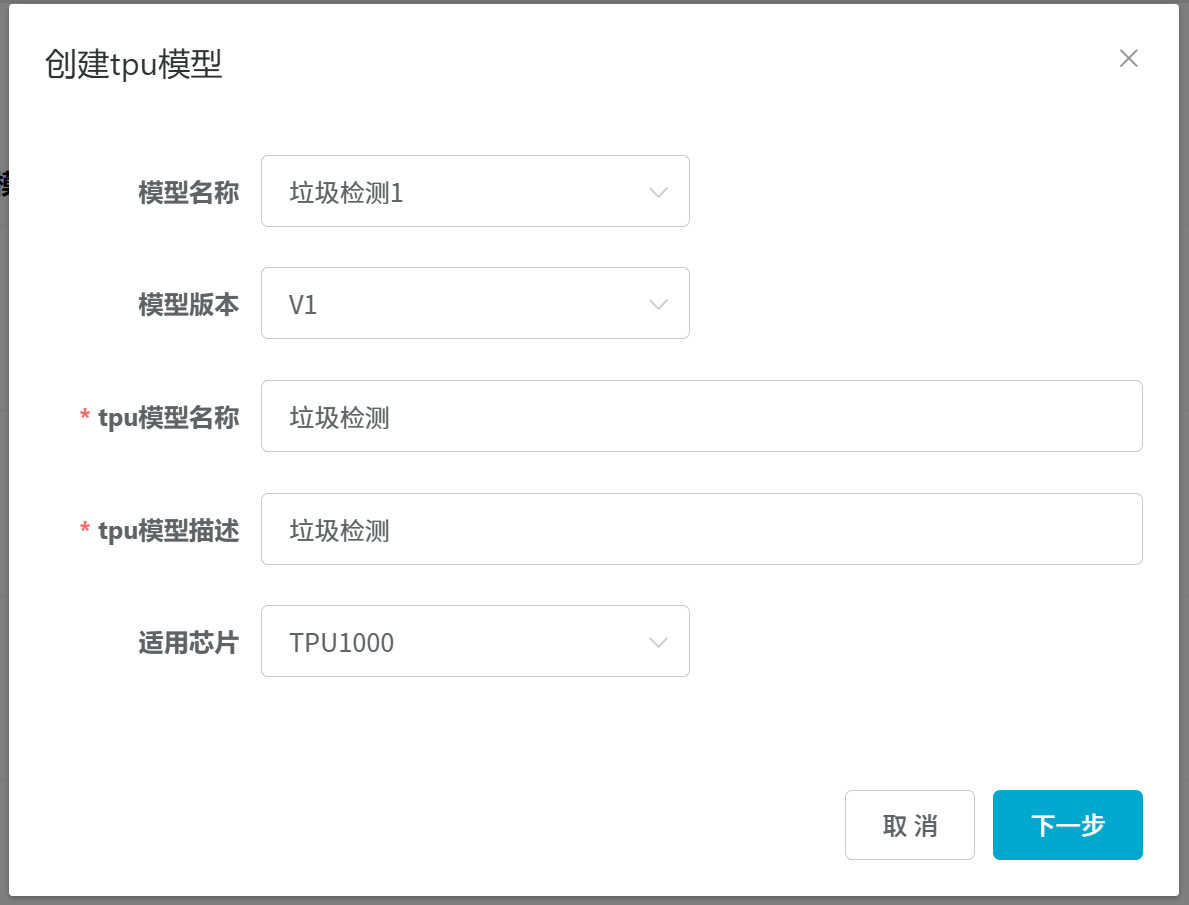 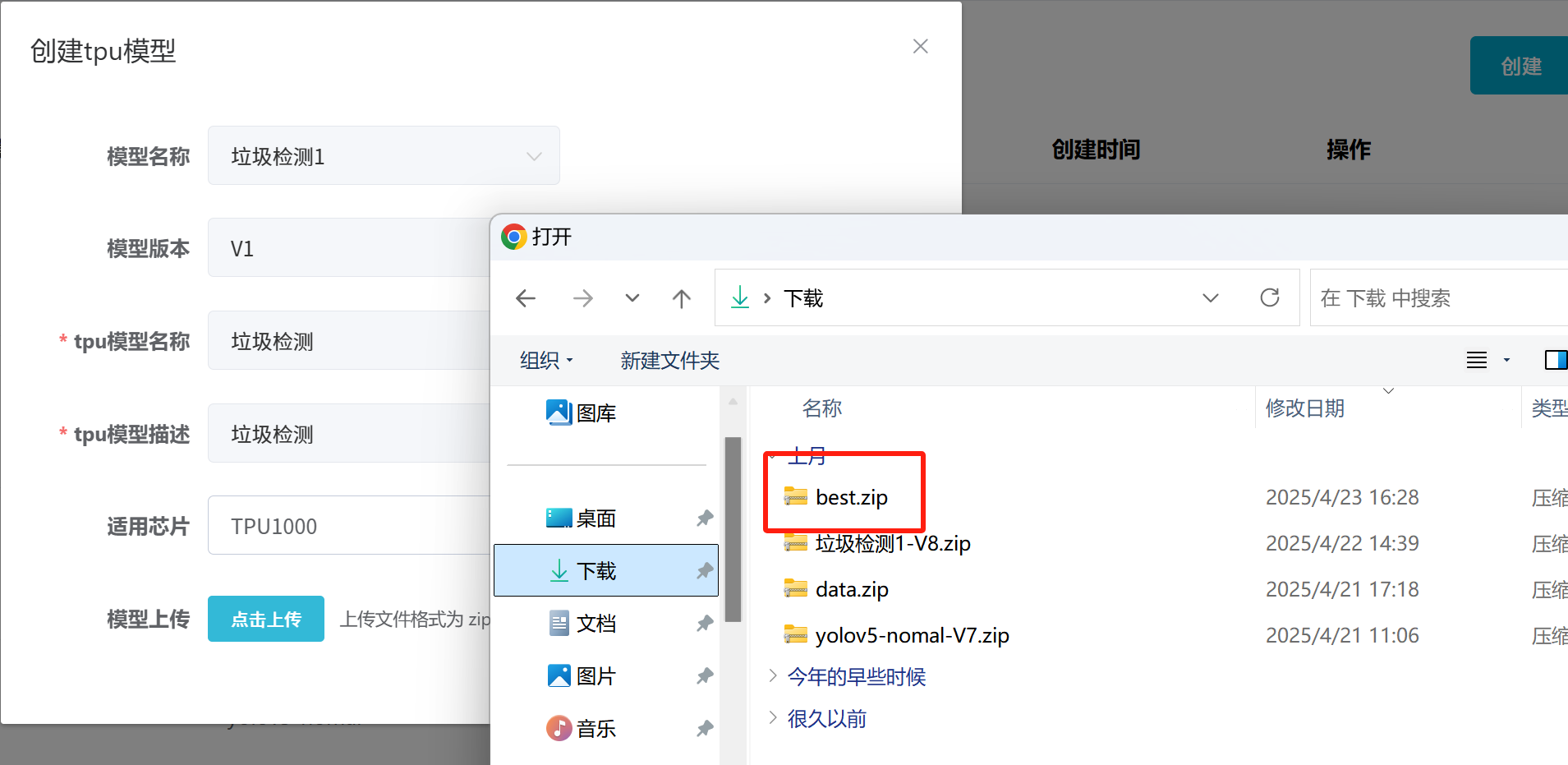 然后我们可以在TPU模型列表中看到我们刚刚创建的TPU模型,然后点击版本列表 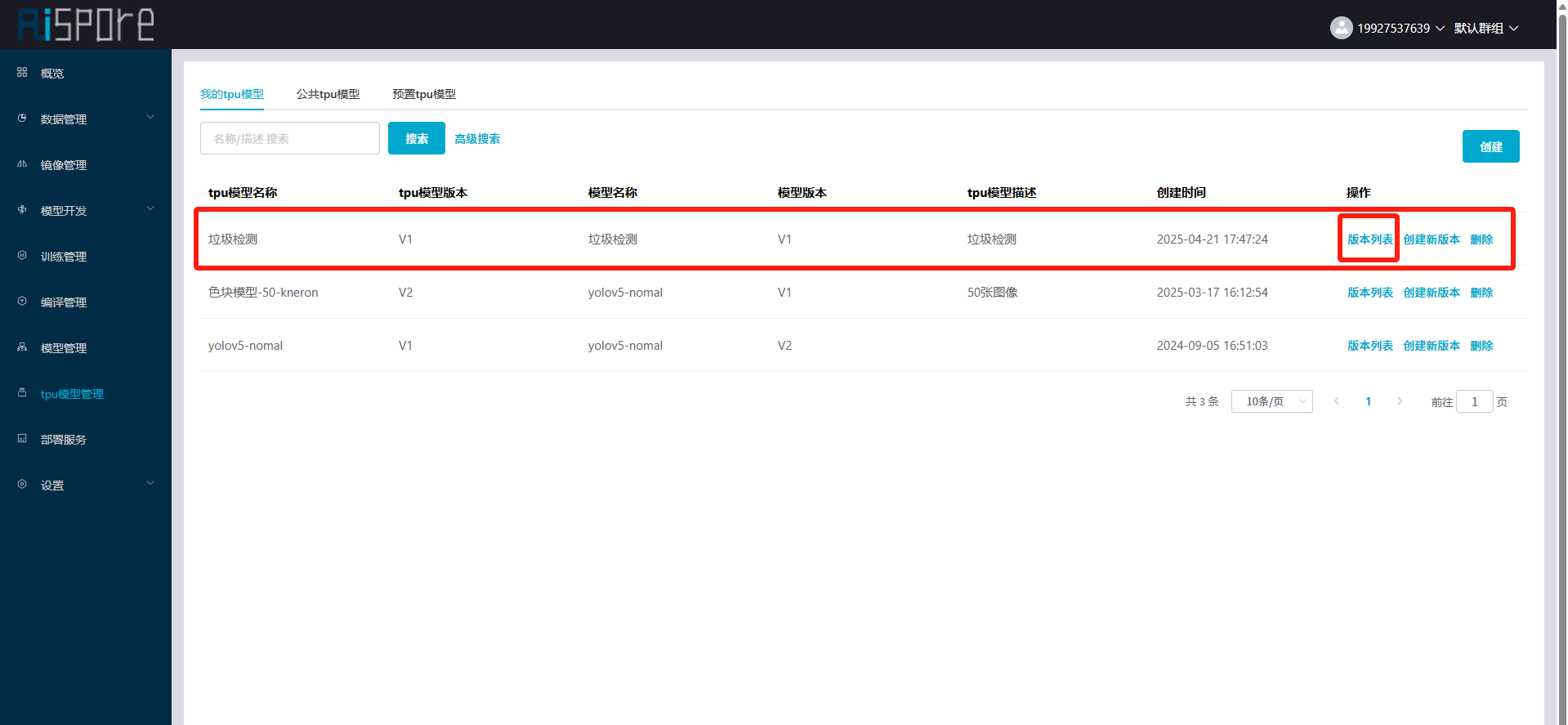 点击固化 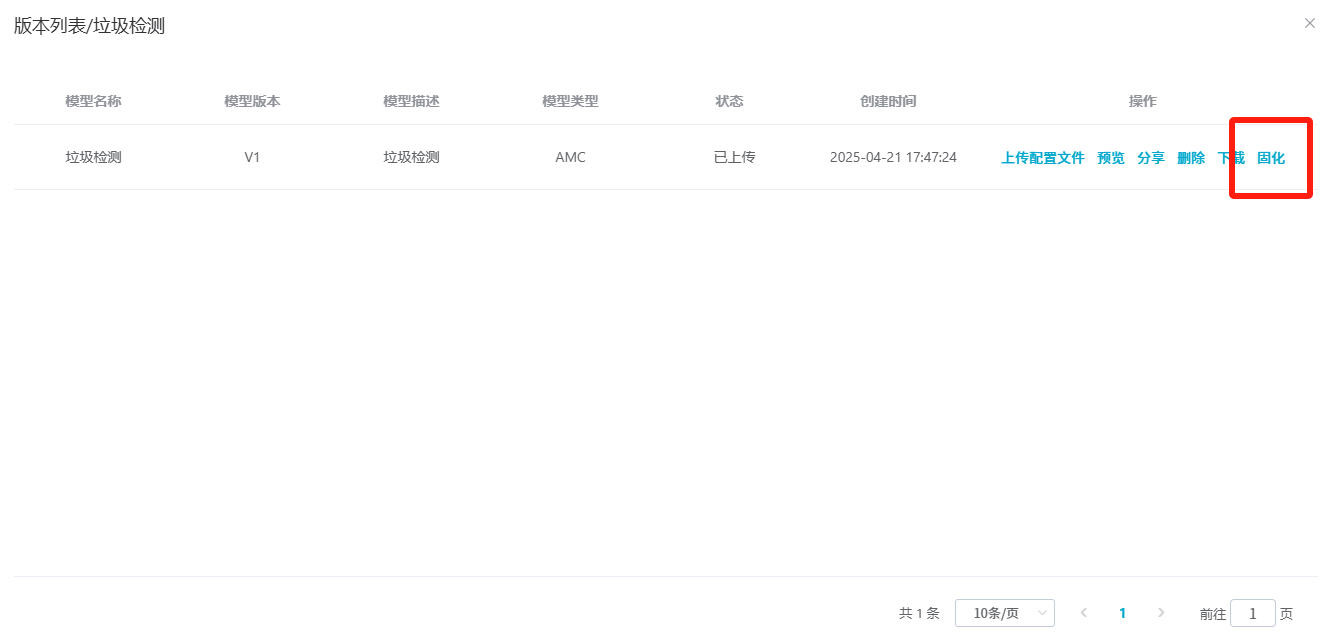 输入TPU模型名称,用于后期TPU接入教具时,教具主板对模型的选择 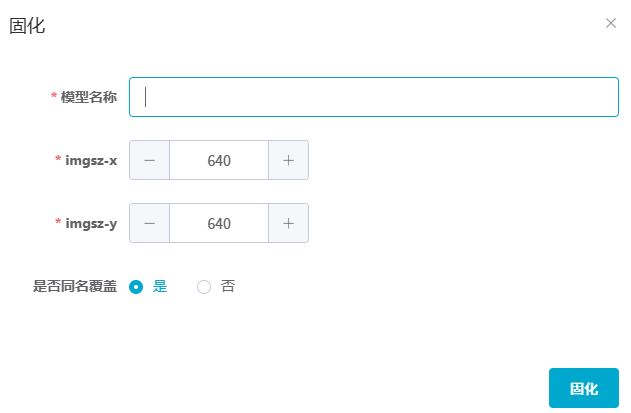 ## 6. 提交模型 当学生确认代码完成可以提交后,回到竞赛平台的团队场次列表下,进行模型评分操作。 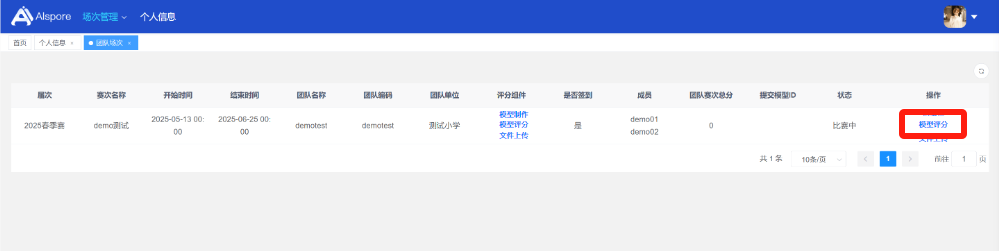 选择上传模型,将在3.5步骤中完成的ZIP文件上传并提交 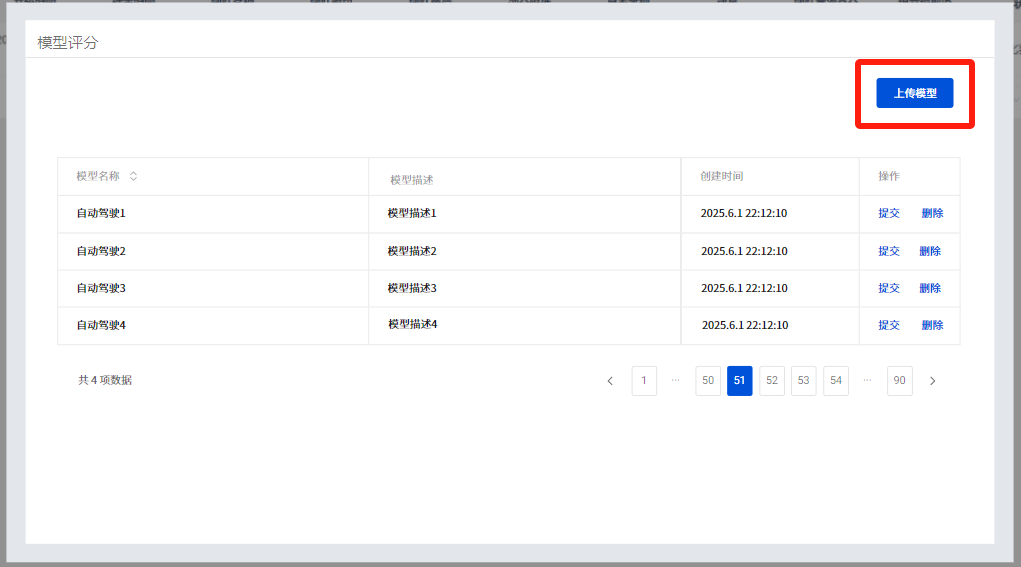 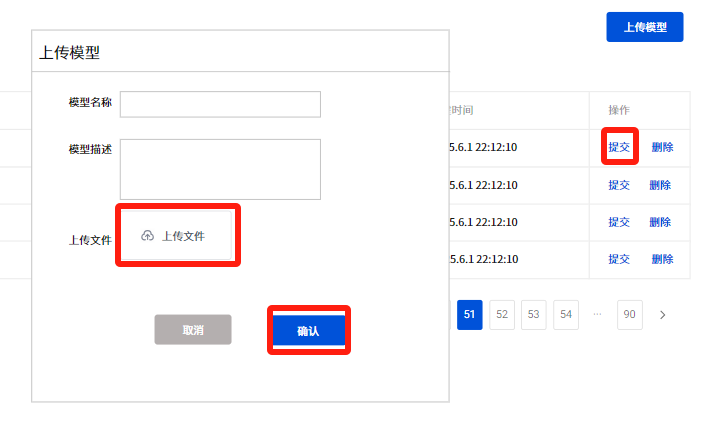 ## 7. 查看评分 学生在比赛时间内可多次提交模型评分,查看模型提交记录与得分。在团队场次列表,可查看团队赛次总分(取最高分为比赛最终得分)。 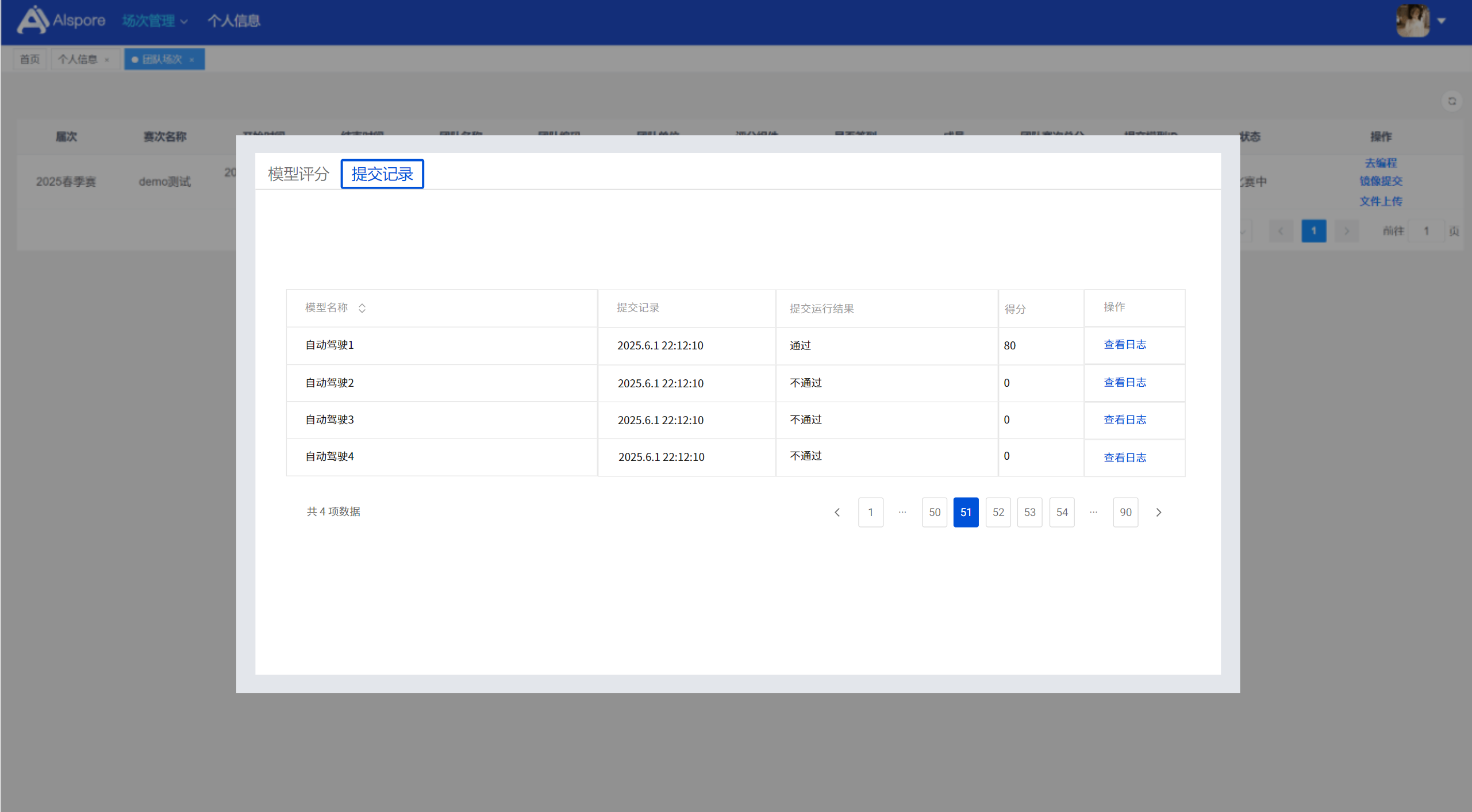 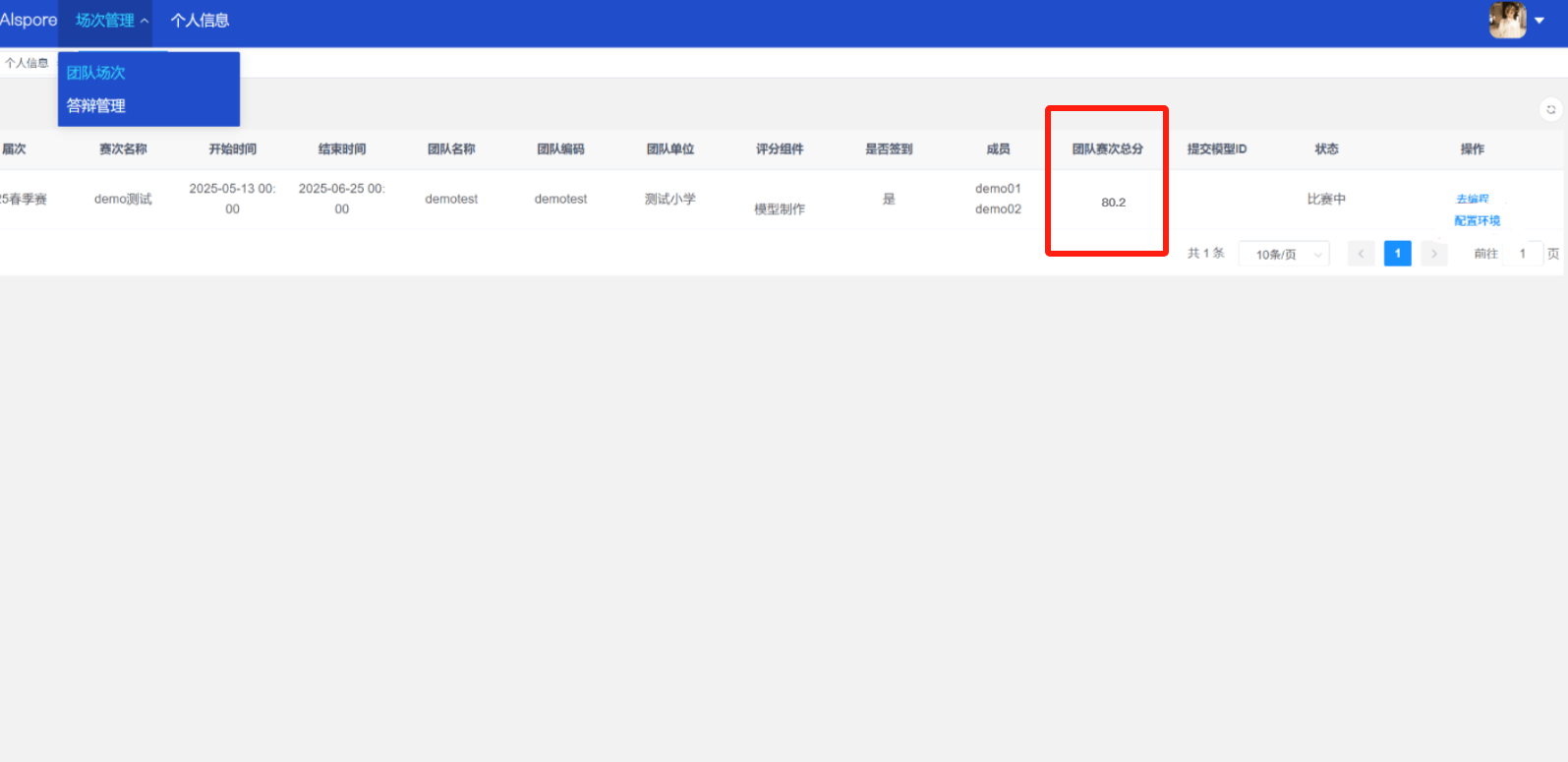 ## 8. 上传作品文件 如果需要进行附件上传(如MP4、PDF文件),回到竞赛平台的团队场次列表下,进行文件上传操作。 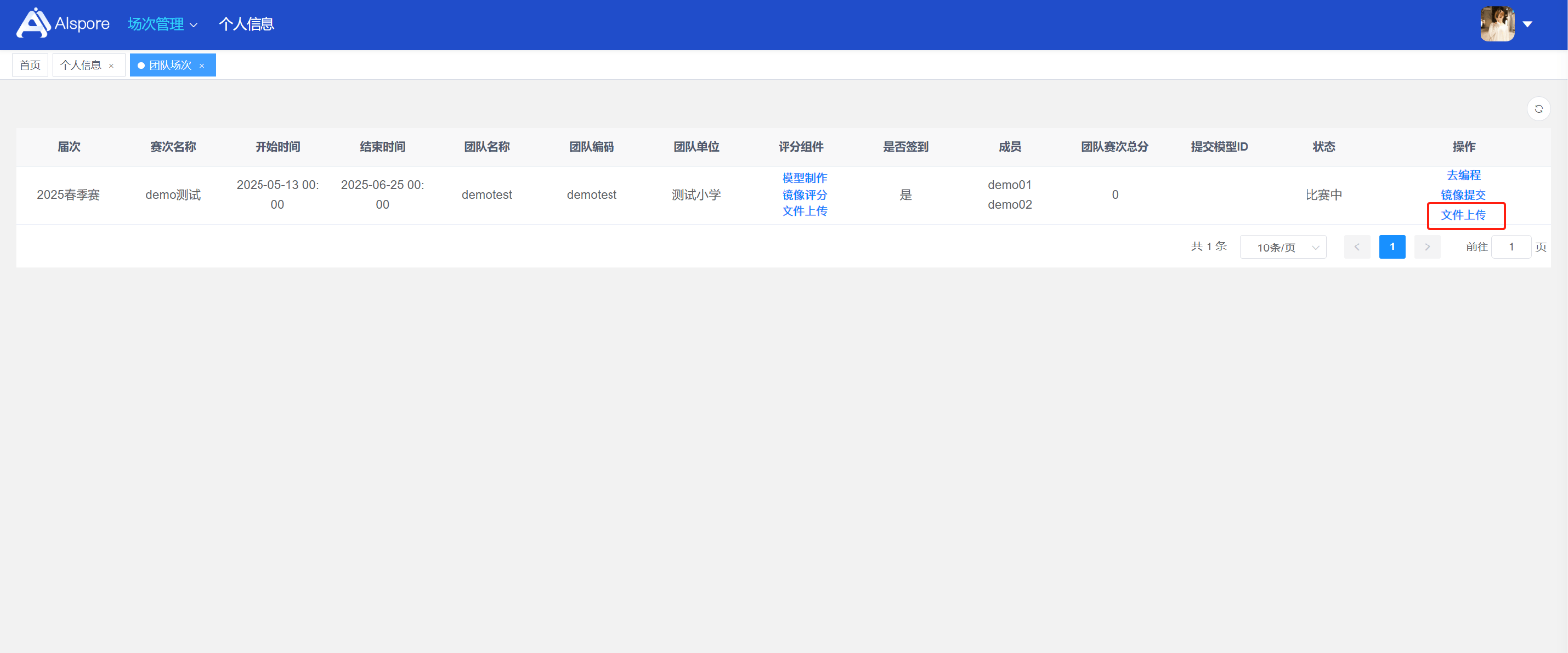 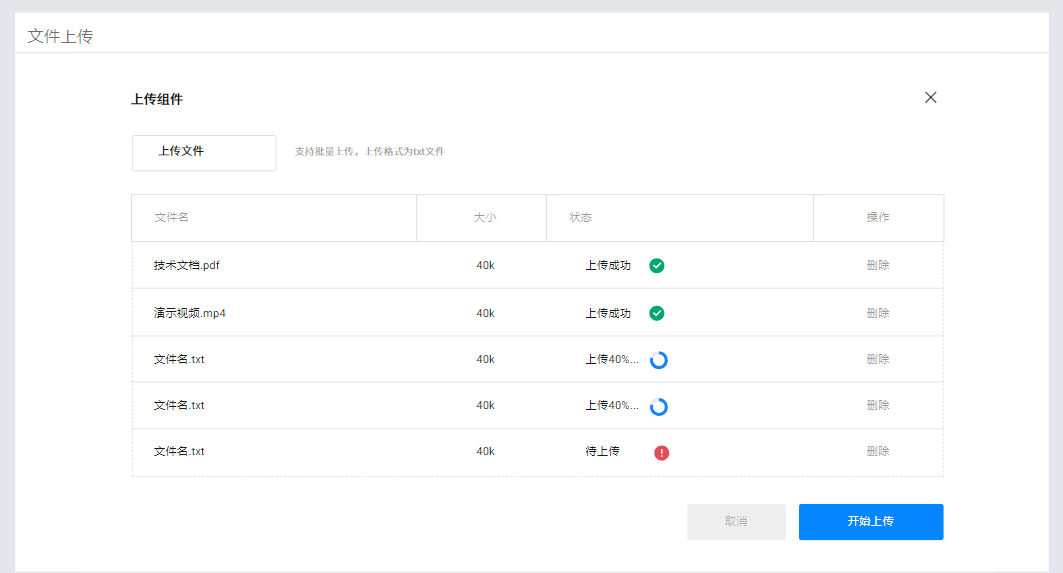
gdsoke
2025年6月27日 10:49
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码